01
KEV0143/Comparative-analysis-of-hourly-load-forecasting-using-PatchTST-TFT-NHiTS-and-CatBoost
+13% /wk +28 ★/day↗accelerating
Pits PatchTST, TFT, and N-HiTS against CatBoost to help energy markets pick a forecasting model.
Pits PatchTST, TFT, and N-HiTS against CatBoost to help energy markets pick a forecasting model.
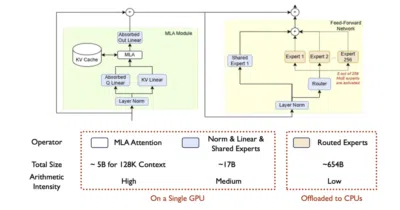
KTransformers makes CPU-GPU heterogeneous inference and fine-tuning for massive MoE models almost practical on consumer hardware.
Curated technical deep-dives covering everything from NVLink signal integrity to Kubernetes GPU scheduling and Huawei NPU porting.
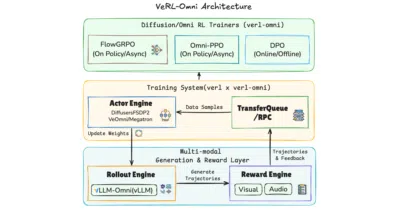
It split off from `verl` to give diffusion, video, and omni-modality models an RL post-training framework that doesn't treat them like chatbots.
Google's edge ML runtime grows up, adds async NPU support, and finally admits PyTorch exists.
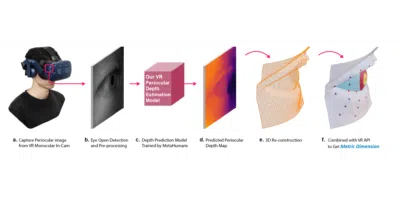
VR eye cameras output flat images, and this project recovers the metric 3D geometry researchers actually need.
Because OpenAI's gym-retro froze, this fork keeps 1,000+ classic games playable as Gymnasium RL environments.
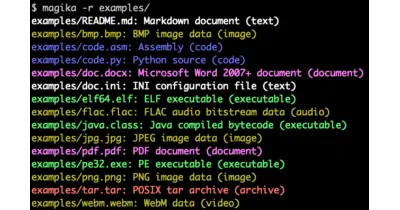
A tiny deep-learning model that guesses what a file actually contains, not just what its extension claims.
It corrals the latest subquadratic sequence-model research into hardware-efficient, training-ready PyTorch layers verified across NVIDIA, AMD, and Intel GPUs.
MLX-VLM crams speculative decoding, continuous batching, and KV cache quantization into a Mac-native toolkit for running multimodal models locally.
A Chinese-language notebook curriculum that teaches LLM inference engineering by rebuilding vLLM and SGLang internals in Python.
A PyTorch implementation of "Attention Is All You Need" that scales from 13M to multi-billion parameter models.
A collection of minimal Python implementations that trade production polish for pedagogical clarity, exposing how classic ML algorithms work under the hood.
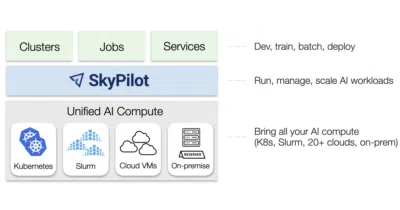
One YAML file runs your AI workload on Kubernetes, Slurm, AWS, or a random GPU cloud you've never heard of.
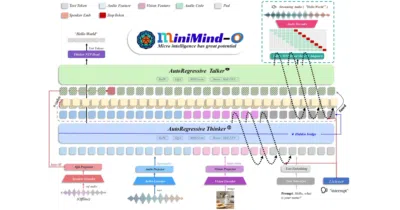
MiniMind-O packs listen-see-speak intelligence into a 0.1B-parameter model you can retrain from the first line of code on a single desktop GPU.
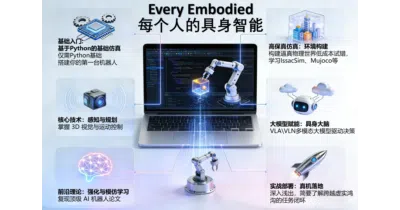
Chinese open-source community Datawhale built a from-zero embodied-AI course that gets you from `print('hello')` to fine-tuning SmolVLA and Pi0.
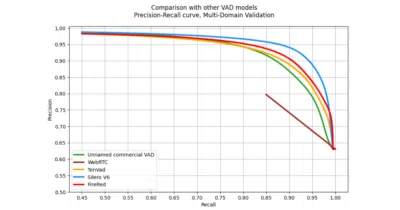
Pre-trained voice activity detection that runs on a CPU thread in under a millisecond, no API keys or telemetry attached.
Course materials that exist because the author thinks certificates are meh and the only way to learn PyTorch is to write hundreds of lines of it.
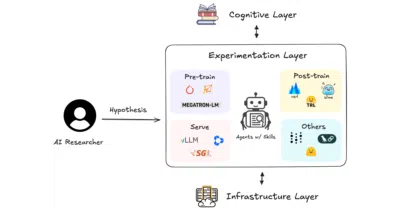
A library of 98 structured skill packs that turns coding agents into end-to-end AI researchers, from distributed training to LaTeX submission.
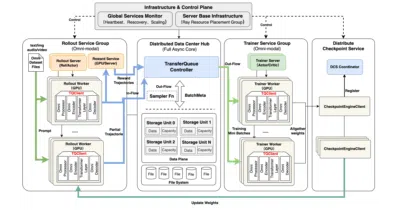
This engine decouples RL training and inference into independent GPU services, letting text, vision, and audio models post-train asynchronously at scale.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.