jingyaogong/minimind-o
The smallest end-to-end Omni model is also the most teachable
MiniMind-O packs listen-see-speak intelligence into a 0.1B-parameter model you can retrain from the first line of code on a single desktop GPU.
Velocity · 7d
+9.7
★ / day
Trend
↗accelerating
star history
What it does
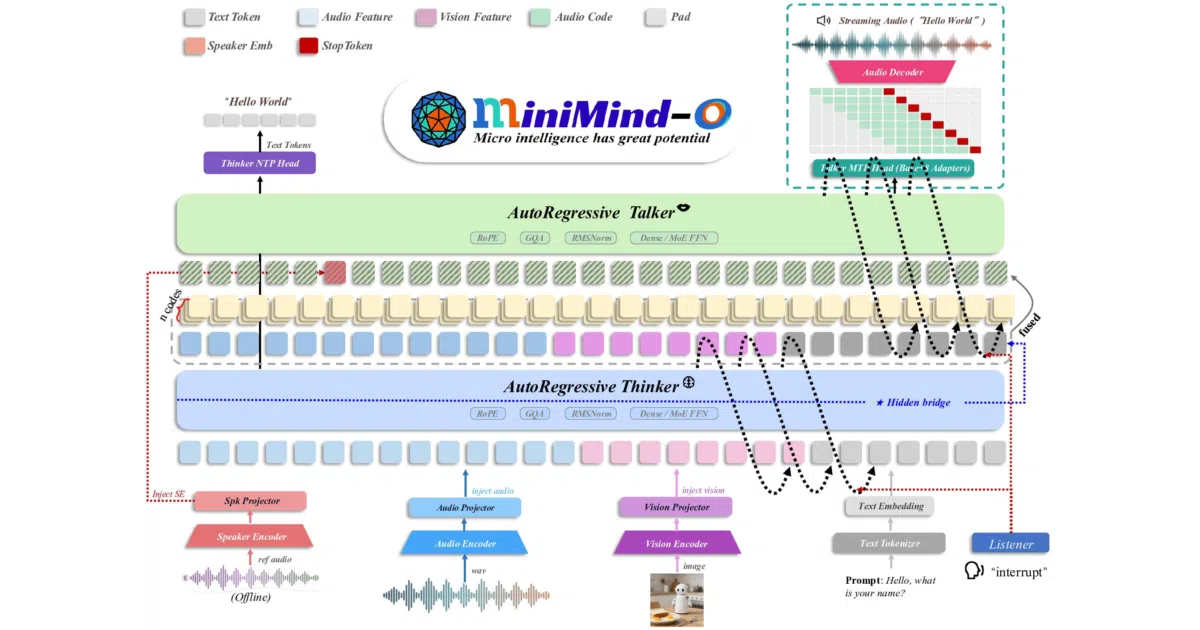
MiniMind-O is the third leg of the MiniMind family, turning the existing language and vision-language models into a full Omni assistant. It ingests text, audio, and images, then replies in text or streams synthesized speech from one modest 0.1B-parameter weight. The repository is essentially a self-contained course: it ships architecture code, training scripts, mini and full datasets, pretrained checkpoints, and an arXiv technical report, all aimed at letting a solo developer read every layer and retrain the pipeline.
The interesting bit
Rather than duct-taping an ASR chain to an LLM and then to a TTS engine—which adds latency and bleeds out tone—MiniMind-O fuses speech and text inside shared hidden states. A Thinker path digests the multimodal input, while a Talker path uses multi-token prediction to spit out layered Mimi audio codes in parallel, yielding 24 kHz streaming voice, real-time barge-in, and speaker cloning without requiring a data center.
Key highlights
- Pocket-sized: The released
minimind-3obackbone is ~0.1B parameters (115M), and the authors bill it as one of the smallest complete open Omni implementations available. - No black boxes: Core algorithms are written in raw PyTorch without high-level third-party wrappers, so the math is exposed and modifiable.
- Borrowed senses: It freezes SenseVoice-Small (audio), SigLIP2 (vision), and the Mimi codec, injecting their features into the model via lightweight two-layer MLP projectors; the novelty is the Omni fusion, not the encoders.
- Interactive tooling: Includes CLI inference, a phone-mode WebUI, VAD-based interruption, streaming playback, and timbre cloning from either built-in prompts or arbitrary reference audio.
- Two-hour proof of concept: The mini dataset reportedly runs through the full Thinker–Talker supervised fine-tuning pipeline in about two hours on one RTX 3090, letting you verify the mechanics before committing to the full dataset.
Caveats
- The WebUI is finicky: you must manually copy a transformers-format model folder into
./scripts/before launching it, or the demo script simply errors out. - “From 0” means the Omni architecture and training loop are built from scratch in PyTorch, but you still bootstrap from a pretrained MiniMind language backbone and frozen specialist encoders.
- The primary documentation is in Chinese; English speakers will need to hunt for the
README_en.mdfile.
Verdict
Ideal for students and hackers who want to touch the internals of an end-to-end voice+vision model without renting a GPU cluster. If you are looking for a production assistant that rivals GPT-4o, this is a classroom, not a competitor.
Frequently asked
- What is jingyaogong/minimind-o?
- MiniMind-O packs listen-see-speak intelligence into a 0.1B-parameter model you can retrain from the first line of code on a single desktop GPU.
- Is minimind-o open source?
- Yes — jingyaogong/minimind-o is open source, released under the Apache-2.0 license.
- What language is minimind-o written in?
- jingyaogong/minimind-o is primarily written in Python.
- How popular is minimind-o?
- jingyaogong/minimind-o has 2.2k stars on GitHub and is currently accelerating.
- Where can I find minimind-o?
- jingyaogong/minimind-o is on GitHub at https://github.com/jingyaogong/minimind-o.