01
PrismML-Eng/Bonsai-demo
+57% /wk +168 ★/day↗accelerating
A demo repo for running extreme-quantized language models locally without needing a research cluster.
A demo repo for running extreme-quantized language models locally without needing a research cluster.
An unofficial proxy that borrows your ChatGPT/Codex OAuth tokens to serve a local OpenAI-compatible API, bypassing API credit billing.
It exists to stop your AI gateway from quietly burning through quotas, cash, and expired OAuth tokens without leaving a paper trail.
It keeps the entire agent loop—prompts, tool calls, browser state, and memory—on your laptop so you don't have to rent a control plane in the cloud.
A Go proxy that tricks Claude Code into using $5/month open models through OpenCode instead of Anthropic's API.
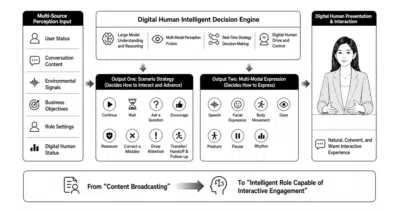
A self-hosted framework for building real-time voice-first AI agents that persist memory, delegate long tasks to background sub-agents, and optionally show up as lip-synced digital humans.
Espressif's C framework turns cheap microcontrollers into edge AI agents you program through IM chat.
One desktop UI that wires together ComfyUI, OpenAI, Gemini, ModelScope, and a dozen other generative APIs—plus some very opinionated legal terms.
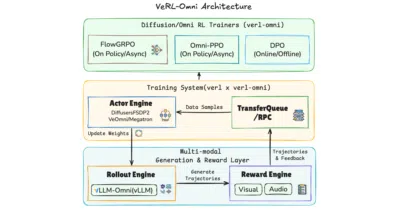
It split off from `verl` to give diffusion, video, and omni-modality models an RL post-training framework that doesn't treat them like chatbots.
turbovec exists so you can index embeddings immediately—no training, no tuning, no rebuilds—and search them faster than FAISS in a fraction of the RAM.
A Bittensor subnet that uses zero-knowledge proofs to verify miners actually ran the AI models they claim to.
AngelSlim integrates quantization, speculative decoding, and distillation so you can shrink and serve massive models from a single toolkit.
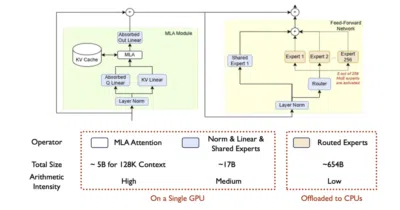
KTransformers makes CPU-GPU heterogeneous inference and fine-tuning for massive MoE models almost practical on consumer hardware.
It turns your local machine into an OpenAI-compatible inference endpoint so agents and IDEs can run on offline models without reconfiguration.
It exists because cloud image generators deserve a local memory layer, a branching canvas, and a UI outside the chat thread.
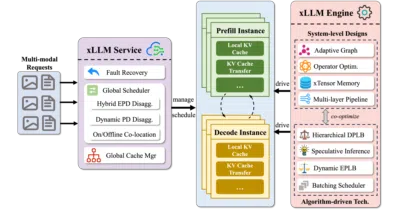
xLLM is a C++ inference framework specifically optimized for Chinese AI accelerators, and it already powers JD.com’s core retail production workloads.
A C/C++ SDK that bundles speech recognition, multimodal AI, and cloud LLM plumbing so Wi-Fi modules and MCUs can behave like smart agents.
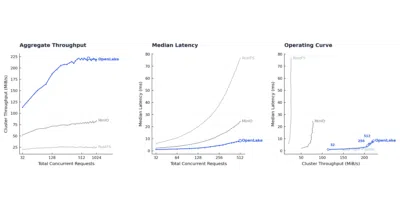
OpenLake wants storage to bypass the host entirely and land straight in GPU memory.
Bytez wraps 175,000+ AI models behind a single endpoint so you don't have to host them yourself.
Because finding the right LTX-2 checkpoint, quantization, or LoRA across Hugging Face and ComfyUI nodes is a part-time job.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.