Orchestra-Research/AI-Research-SKILLs
An ML syllabus for agents that want to do AI research
A library of 98 structured skill packs that turns coding agents into end-to-end AI researchers, from distributed training to LaTeX submission.
Velocity · 7d
+34
★ / day
Trend
→steady
star history
What it does
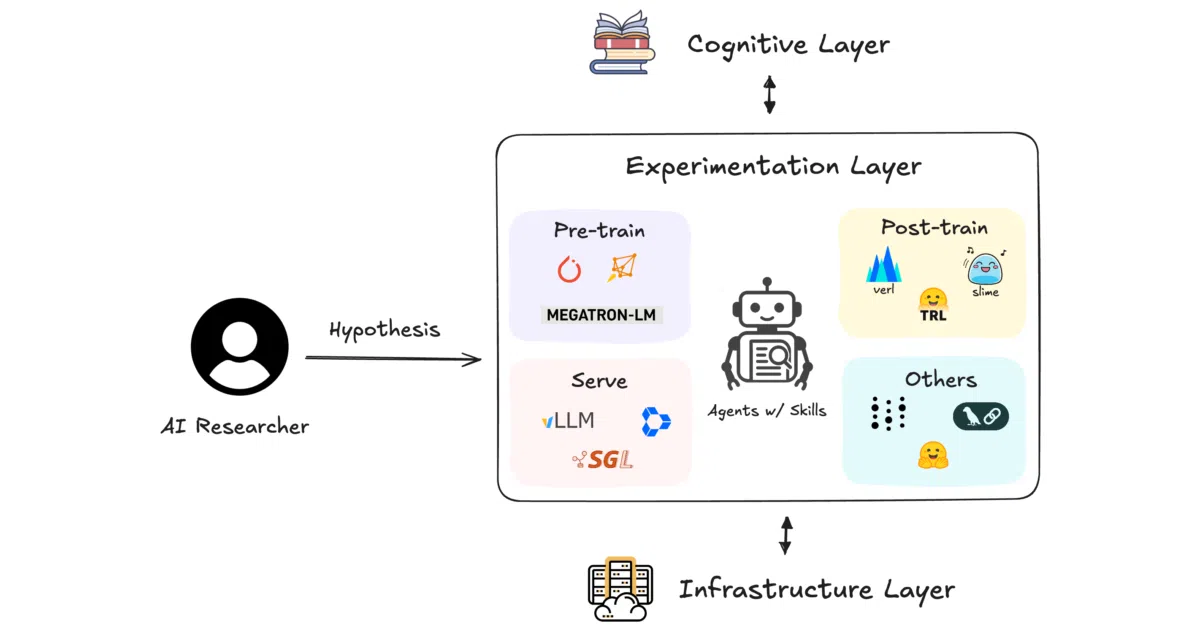
This repository is a curated library of 98 agent “skills” spanning 23 categories, from Megatron-Core and vLLM to mechanistic interpretability and LaTeX paper writing. Each skill is a dense knowledge pack—complete with line counts and reference citations—that teaches coding agents like Claude Code or Gemini how to execute a specific research or engineering task. A central autoresearch skill attempts to orchestrate the full pipeline, routing an agent from literature review through experiments to paper writing.
The interesting bit
Instead of shipping new model code, the project treats agent context windows as a shared research notebook. It is essentially a meta-layer: weeks of framework-specific debugging knowledge compressed into structured documentation so an agent can stop hallucinating config.yaml keys and start running distributed training jobs.
Key highlights
- 98 skills across 23 categories, including post-training (
GRPO,OpenRLHF,verl), inference (vLLM,TensorRT-LLM,SGLang), fine-tuning (Axolotl,Unsloth), and multimodal (LLaVA,Stable Diffusion). - An
autoresearchorchestration layer with a two-loop architecture (inner optimization plus outer synthesis) that manages the research lifecycle. - Skills cite line counts and reference tallies (e.g., the GRPO skill is 569 lines with 4 refs), suggesting self-contained, dense documentation rather than sprawling wikis.
- Distributed through both an npm-based installer and the Claude Code
/pluginmarketplace, with auto-detection for several popular agent environments. - Includes “ML Paper Writing” skills with LaTeX templates and citation verification, acknowledging that research ends in a PDF, not just a training log.
Verdict If you are already using Claude Code or another agent and want a pre-loaded syllabus for the modern ML stack, this saves you from writing your own prompts. If you are looking for a novel training framework or a human-readable tutorial site, look elsewhere.
Frequently asked
- What is Orchestra-Research/AI-Research-SKILLs?
- A library of 98 structured skill packs that turns coding agents into end-to-end AI researchers, from distributed training to LaTeX submission.
- Is AI-Research-SKILLs open source?
- Yes — Orchestra-Research/AI-Research-SKILLs is open source, released under the MIT license.
- What language is AI-Research-SKILLs written in?
- Orchestra-Research/AI-Research-SKILLs is primarily written in TeX.
- How popular is AI-Research-SKILLs?
- Orchestra-Research/AI-Research-SKILLs has 11k stars on GitHub and is currently holding steady.
- Where can I find AI-Research-SKILLs?
- Orchestra-Research/AI-Research-SKILLs is on GitHub at https://github.com/Orchestra-Research/AI-Research-SKILLs.