kvcache-ai/ktransformers
Run 671B MoE models on a single RTX 4090 (sort of)
KTransformers makes CPU-GPU heterogeneous inference and fine-tuning for massive MoE models almost practical on consumer hardware.
Velocity · 7d
+223
★ / day
Trend
↗accelerating
star history
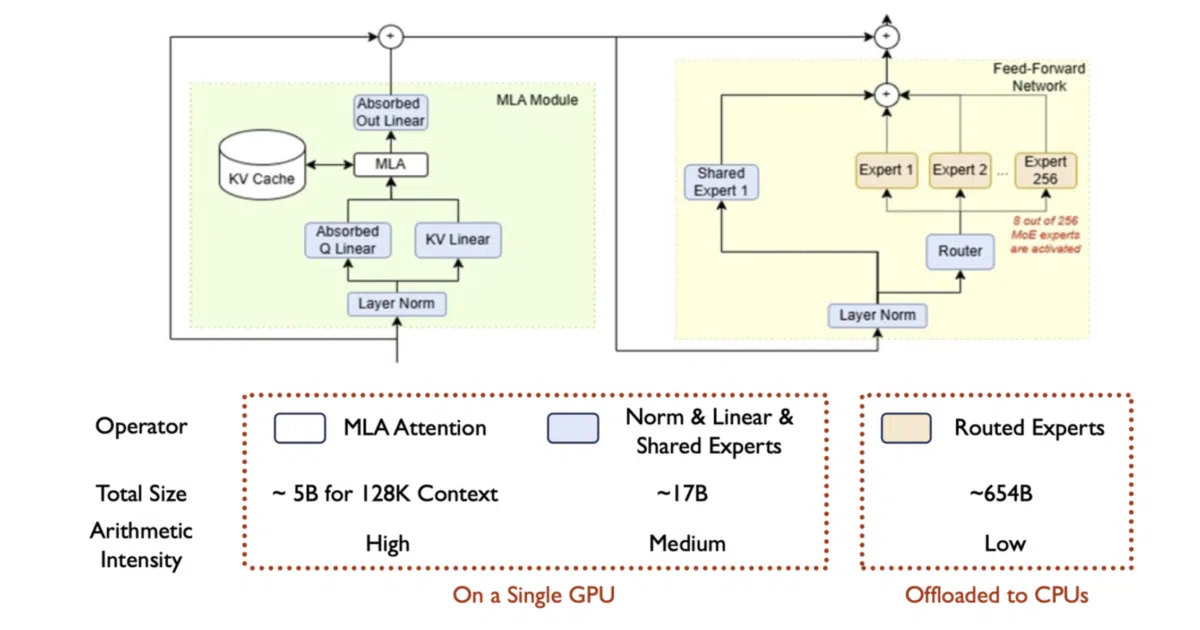
What it does KTransformers is a CPU-GPU heterogeneous computing framework for inference and fine-tuning of large language models, with a heavy focus on Mixture-of-Experts (MoE) architectures. It splits work between GPU and CPU—often keeping “cold” experts in system memory while “hot” ones live in VRAM—so you can run models like DeepSeek-V3/R1 on hardware that shouldn’t be able to hold them.
The project now exposes two main paths: a high-performance inference kernel (kt-kernel) and an SFT integration with LLaMA-Factory. Both lean on aggressive quantization (INT4/INT8 on CPU, GPTQ/FP8 on GPU) and Intel AMX/AVX kernel optimizations to squeeze performance out of mismatched hardware.
The interesting bit The expert scheduling is the clever part: instead of treating all 256 experts as equally GPU-resident, it profiles which ones fire frequently and parks the rest in CPU memory or even on disk. The prefix cache goes three layers deep (GPU → CPU → disk) for reuse across turns. It’s a memory hierarchy strategy dressed up as an LLM serving framework.
Key highlights
- Runs DeepSeek-R1/V3 on single 24GB GPU + 382GB DRAM, with claimed 3–28× speedup over baseline offloading
- SFT integration with LLaMA-Factory reports 6–12× training speedup vs. ZeRO-Offload for MoE fine-tuning, using ~half the CPU memory of prior KT paths
- Intel AMX/AVX512/AVX2 kernels for quantized CPU inference; also supports AMD ROCm, Intel Arc, and Ascend NPU
- Native FP8 per-channel precision and CPU-GPU expert scheduling with NUMA awareness
- Integrates into SGLang for production serving; clean Python API for injection into existing stacks
Caveats
- The “3–28× speedup” claim is from the project’s own benchmarks; no independent verification is cited
- “Day0 support” for new models (GLM-5, MiniMax-M2.5, Kimi-K2.5) suggests rapid but potentially brittle adaptation
- Original monolithic framework was archived; current split into
kt-kernel+ SFT docs is recent (v0.6.1, April 2026) and may still be settling
Verdict Worth a look if you’re trying to serve or fine-tune 100B+ MoE models on commodity hardware and don’t mind tuning quantization tradeoffs. If you have uniform H100 clusters and ample VRAM, this adds complexity you probably don’t need.
Frequently asked
- What is kvcache-ai/ktransformers?
- KTransformers makes CPU-GPU heterogeneous inference and fine-tuning for massive MoE models almost practical on consumer hardware.
- Is ktransformers open source?
- Yes — kvcache-ai/ktransformers is open source, released under the Apache-2.0 license.
- What language is ktransformers written in?
- kvcache-ai/ktransformers is primarily written in Python.
- How popular is ktransformers?
- kvcache-ai/ktransformers has 18.9k stars on GitHub and is currently accelerating.
- Where can I find ktransformers?
- kvcache-ai/ktransformers is on GitHub at https://github.com/kvcache-ai/ktransformers.