google/magika
Google's file-type oracle fits in a few megabytes
A tiny deep-learning model that guesses what a file actually contains, not just what its extension claims.
Not currently ranked — collecting fresh signals.
star history
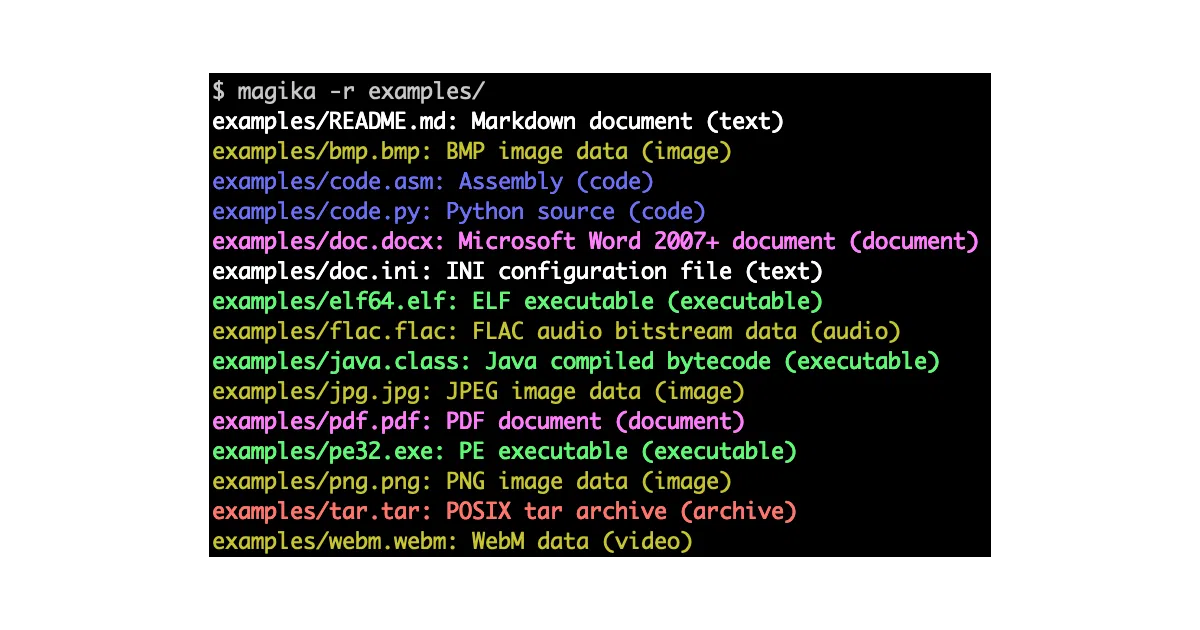
What it does Magika identifies file content types—binary or text—using a lightweight neural network. It reads only a limited slice of each file, runs inference in about 5 ms on a single CPU, and outputs MIME types, labels, or confidence scores. Google uses it to route Gmail, Drive, and Safe Browsing files to the correct security scanners, processing hundreds of billions of files weekly.
The interesting bit The model weighs only a few megabytes and was trained on ~100M files across 200+ content types. It is fast enough to be near-constant time regardless of file size, because it deliberately ignores most of the bytes. That is the opposite of the usual “throw more data at the transformer” playbook.
Key highlights
- CLI written in Rust; bindings for Python, JavaScript/TypeScript (experimental), and Go (WIP)
- ~99% average precision and recall on the test set, with particular strength on textual formats
- Per-content-type confidence thresholds: can return generic labels like “Unknown binary data” when uncertain
- Three prediction modes:
high-confidence,medium-confidence, andbest-guess - Web demo runs entirely in the browser; no install required
Caveats
- The Go binding is marked work-in-progress
- The npm package is labeled experimental
- The README notes this is “not an official Google project” and carries no support or warranty
Verdict
Worth a look if you process untrusted uploads, run security pipelines, or just want a faster file command. Skip it if you only ever handle files with honest extensions and no adversarial users.
Frequently asked
- What is google/magika?
- A tiny deep-learning model that guesses what a file actually contains, not just what its extension claims.
- Is magika open source?
- Yes — google/magika is open source, released under the Apache-2.0 license.
- What language is magika written in?
- google/magika is primarily written in Python.
- How popular is magika?
- google/magika has 17.3k stars on GitHub.
- Where can I find magika?
- google/magika is on GitHub at https://github.com/google/magika.