FareedKhan-dev/train-llm-from-scratch
Build a transformer from scratch on a single GPU
A PyTorch implementation of "Attention Is All You Need" that scales from 13M to multi-billion parameter models.
Velocity · 7d
+23
★ / day
Trend
↘cooling
star history
What it does
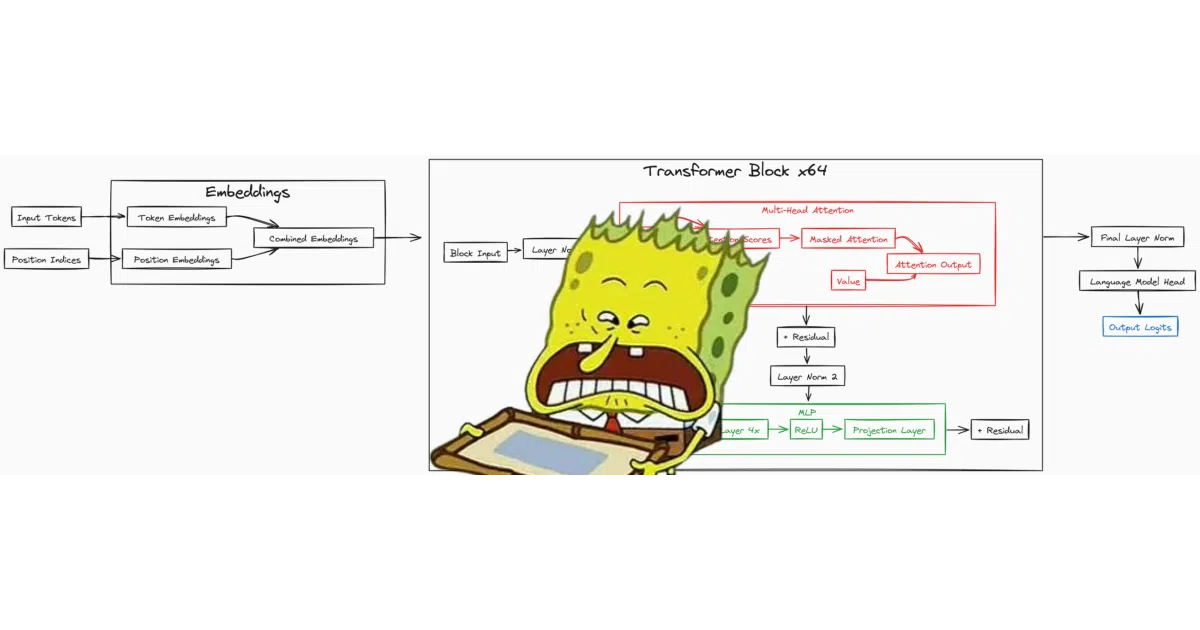
This repo implements a full transformer architecture in raw PyTorch—attention heads, MLP blocks, the works—and wraps it in scripts to download data (the 825GB Pile dataset), preprocess it, train the model, and generate text. The author claims you can train models from 13 million up to a few billion parameters on a single GPU, with a detailed GPU memory chart showing what fits where.
The interesting bit
The value isn’t the model (it’s standard transformer stuff) but the educational scaffolding: every component is broken out into its own file, and the README walks through each piece from single-head attention up to the full model. It’s essentially a runnable textbook chapter. The included sample output from the 13M model is charmingly incoherent—“The park was returned to the factory-plate”—which honestly sets expectations honestly.
Key highlights
- Pure PyTorch, no
transformerslibrary hiding the mechanics - Scripts for data download, preprocessing, training, and generation
- GPU compatibility table covering 25+ cards from GTX 1660 Ti to A100
- Uses the Pile dataset (22 diverse sources, 825GB total)
- Config-driven: tweak
config/config.pyandsrc/models/transformer.pyto resize the model
Caveats
- The README is truncated mid-config-snippet, so the exact billion-parameter setup is cut off
- No training curves, loss numbers, or evaluation metrics are shown beyond one sample output
- The “2B LLM training” claims for consumer cards are theoretical; only the 13M model has demonstrated output
Verdict
Grab this if you’re a student or practitioner who wants to see transformer internals without HuggingFace abstractions. Skip it if you need production training infrastructure, distributed setup, or proof that the larger configs actually converge.
Frequently asked
- What is FareedKhan-dev/train-llm-from-scratch?
- A PyTorch implementation of "Attention Is All You Need" that scales from 13M to multi-billion parameter models.
- Is train-llm-from-scratch open source?
- Yes — FareedKhan-dev/train-llm-from-scratch is open source, released under the MIT license.
- What language is train-llm-from-scratch written in?
- FareedKhan-dev/train-llm-from-scratch is primarily written in Python.
- How popular is train-llm-from-scratch?
- FareedKhan-dev/train-llm-from-scratch has 8.5k stars on GitHub and is currently cooling off.
- Where can I find train-llm-from-scratch?
- FareedKhan-dev/train-llm-from-scratch is on GitHub at https://github.com/FareedKhan-dev/train-llm-from-scratch.