01
shiyu-coder/Kronos
+225 ★/day↗accelerating
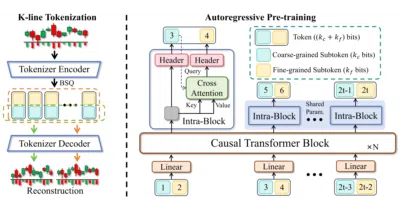
Kronos recasts noisy, multi-dimensional candlestick data as hierarchical discrete tokens so an autoregressive Transformer can forecast financial markets like a language model.
Kronos recasts noisy, multi-dimensional candlestick data as hierarchical discrete tokens so an autoregressive Transformer can forecast financial markets like a language model.
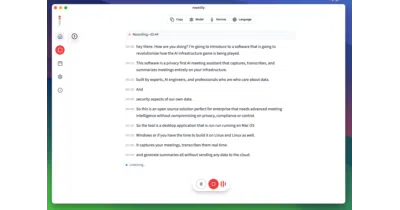
Meetily transcribes and summarizes meetings entirely on-device, because "we don't log your calls" is a promise best kept by physics.
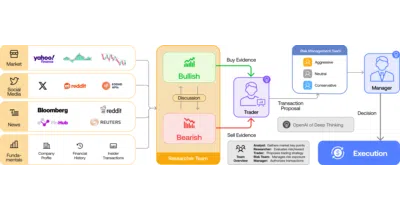
A research framework that assigns LLMs to trading-floor roles—analyst, researcher, trader, risk manager—to debate and execute simulated stock decisions.
Official Jupyter notebooks demonstrating how to wire Claude into production tasks like RAG, SQL queries, and multimodal pipelines.
It exists to run large language models on virtually any hardware—from Apple Silicon to RISC-V to your browser—with zero external dependencies and minimal setup.
Because swapping from GPT-4o to Claude shouldn't require rewriting your request plumbing.
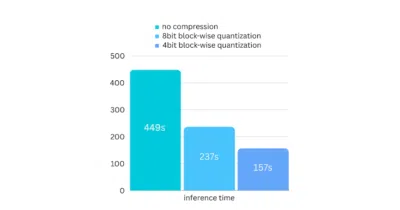
AirLLM slices giant transformers into layer shards so they fit in consumer VRAM without quantization or distillation.
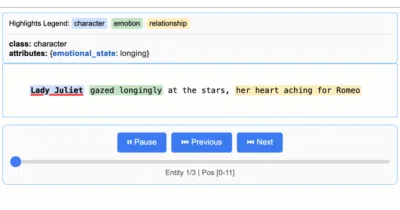
LangExtract exists because asking an LLM to pull names and dates out of a report is easy; proving exactly which sentence each came from is the hard part.
MiniMind is an educational training ground that rebuilds every stage of a modern language model—from tokenizer to RLHF—in raw PyTorch so you can see the gears turning instead of just calling high-level APIs.
It teaches how LLMs work by implementing tokenization, attention, pretraining, and finetuning in pure PyTorch, one notebook at a time.
It exists so you can download, run, and chat with open-weight LLMs locally through one CLI and REST API, keeping inference on your own silicon.
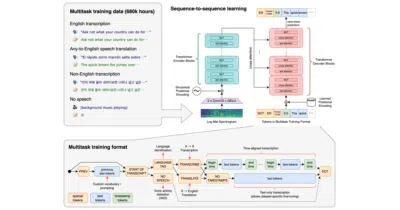
To give developers a single, general-purpose speech model that handles transcription, translation, and language identification by treating tasks as tokens to predict.
GraphRAG exists to give LLMs a structured memory layer for reasoning over messy, private narrative text.
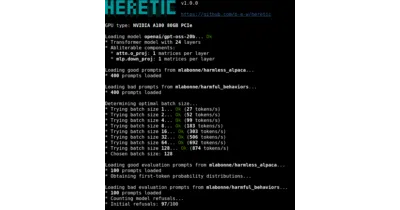
It automates the removal of transformer safety alignment so you don't have to hand-tune abliteration parameters or pay for expensive post-training.
SGLang exists to push low-latency, high-throughput inference for LLMs and multimodal models from a single GPU up to massive clusters.
A Python framework for building production multi-agent systems that leans on LLM reasoning instead of rigid prompt choreography.
It centralizes model definitions so the same architecture works across PyTorch, JAX, vLLM, and llama.cpp without rewrites.
A rewrite of minGPT that prioritizes working, hackable training code over educational scaffolding.
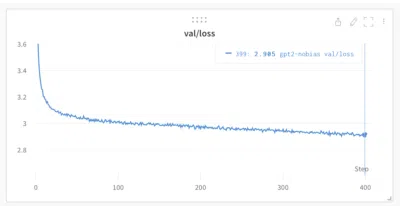
nanochat is a minimal, hackable harness that lets you train and chat with a GPT-2-class LLM on a single GPU node for under $100—no hyperparameter spreadsheets required.
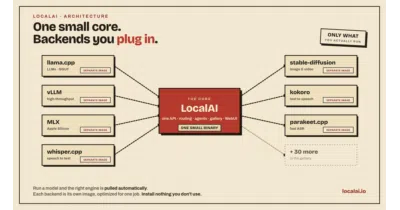
LocalAI wraps 36+ inference engines behind one OpenAI-compatible API and pulls them on demand, so you can run LLMs, vision, voice, and video on anything from a CPU to a Jetson.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.