google/langextract
LLM extraction that points to exactly where it found everything
LangExtract exists because asking an LLM to pull names and dates out of a report is easy; proving exactly which sentence each came from is the hard part.
Velocity · 7d
+84
★ / day
Trend
↗accelerating
star history
What it does
LangExtract is a Python library that feeds unstructured text—clinical notes, novels, reports—to an LLM and returns structured extractions like characters, medications, or relationships. You define the task with a short prompt and a few examples, and the library enforces a strict output schema. For long documents, it chunks the text, processes chunks in parallel, and can run multiple passes to improve recall.
The interesting bit
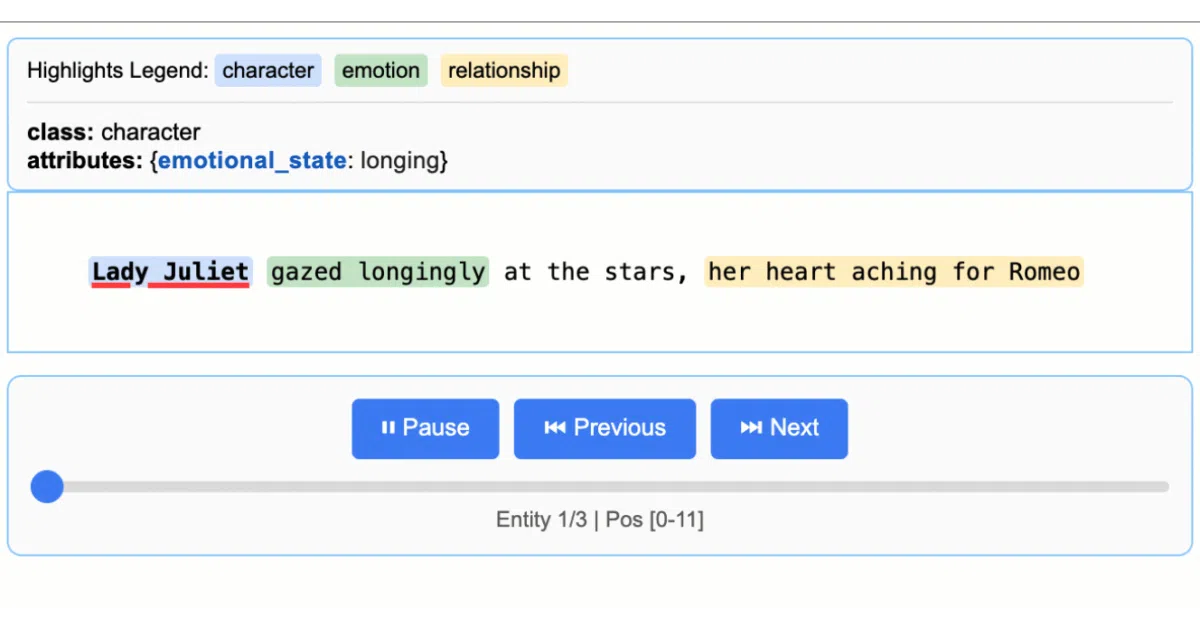
The library treats source grounding as a first-class concern: every extraction is mapped to exact character intervals in the original text, and if the model hallucinates something from your few-shot examples instead of the input, the result gets a char_interval = None flag so you can filter it out. It also spits out a self-contained interactive HTML file that highlights thousands of entities in context—no frontend build required.
Key highlights
- Precise source grounding: every extraction maps to exact character intervals in the original text
- Long-document handling: chunks text and runs parallel extraction passes for higher recall on books or large reports
- Flexible backends: works with Gemini, OpenAI, or local models via Ollama, plus Vertex AI Batch API for cost savings at scale
- Controlled generation: enforces structured output schemas on supported models rather than hoping JSON parses correctly
- Domain-agnostic: define any extraction task with a few examples and a prompt—no fine-tuning necessary
Caveats
- Cloud-hosted models require API keys, and the README suggests a paid Gemini tier for production throughput to avoid rate limits
- Gemini models have defined retirement dates, so you’ll need to track model lifecycle documentation to avoid surprises
Verdict
Worth a look if you need auditable entity extraction from long documents without training a custom model. Skip it if your current regex pipeline is already bulletproof—this is still an LLM doing probabilistic guesswork under the hood.
Frequently asked
- What is google/langextract?
- LangExtract exists because asking an LLM to pull names and dates out of a report is easy; proving exactly which sentence each came from is the hard part.
- Is langextract open source?
- Yes — google/langextract is open source, released under the Apache-2.0 license.
- What language is langextract written in?
- google/langextract is primarily written in Python.
- How popular is langextract?
- google/langextract has 37.7k stars on GitHub and is currently accelerating.
- Where can I find langextract?
- google/langextract is on GitHub at https://github.com/google/langextract.