mudler/LocalAI
An AI engine that unbundles backends and runs on anything with a CPU
LocalAI wraps 36+ inference engines behind one OpenAI-compatible API and pulls them on demand, so you can run LLMs, vision, voice, and video on anything from a CPU to a Jetson.
Velocity · 7d
+29
★ / day
Trend
↗accelerating
star history
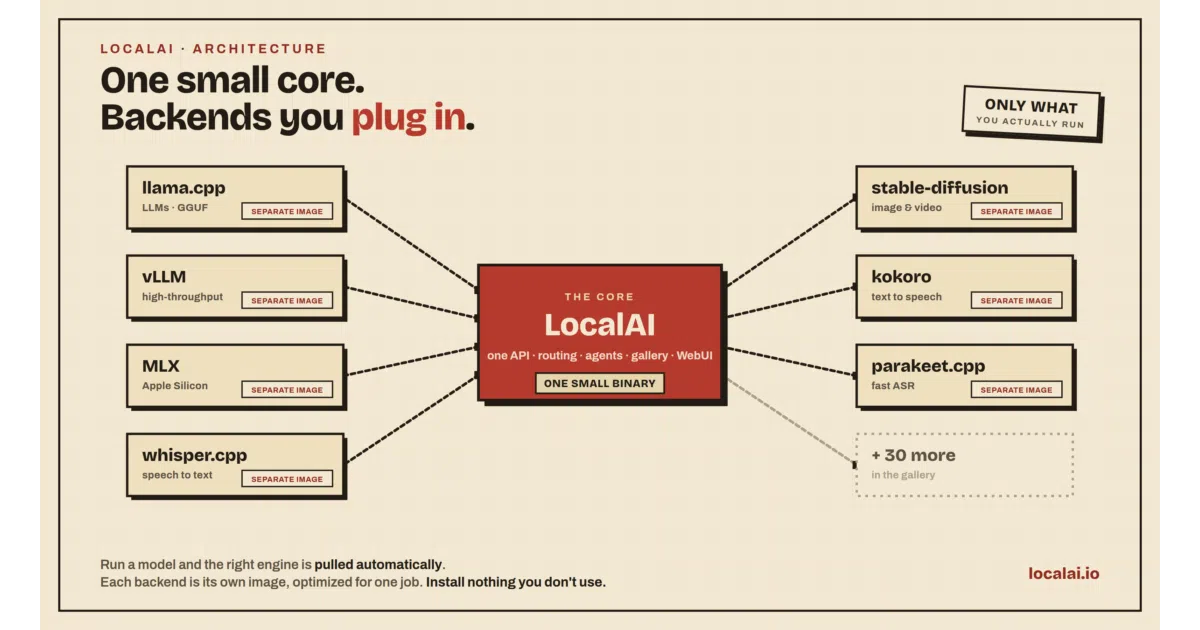
What it does LocalAI is a self-hosted inference server that exposes LLMs, image generators, speech recognizers, and video models through a single OpenAI-compatible API. It wraps more than 36 specialized backends—llama.cpp, vLLM, MLX, whisper.cpp, stable-diffusion—in separate OCI images that are fetched only when a model actually needs them, so the core stays small. It runs on NVIDIA, AMD, Intel, Apple Silicon, Vulkan, or plain CPUs, and includes built-in multi-user auth, quotas, and role-based access.
The interesting bit Instead of shipping one bloated binary, LocalAI acts like a control tower: it detects your hardware, downloads the right backend container on the fly, and routes requests accordingly. Recent releases added distributed cluster mode with VRAM-aware autoscaling, WebRTC realtime audio, and an agent framework with MCP tool use.
Key highlights
- Drop-in compatibility with OpenAI, Anthropic, and ElevenLabs APIs across every backend
- 36+ backends including llama.cpp, vLLM, transformers, diffusers, MLX, and whisper.cpp
- Runs on NVIDIA (CUDA 12/13), AMD ROCm, Intel oneAPI, Apple Silicon Metal, Vulkan, or CPU-only
- Multi-user platform with API keys, per-user quotas, and OIDC support
- Built-in autonomous agents with RAG, MCP, tool streaming, and skills
- Distributed mode for horizontal scaling across clusters with PostgreSQL and NATS
- Privacy-first: data never leaves your infrastructure
Caveats
- The macOS DMG is not signed by Apple, requiring a manual quarantine removal before it will run
- Backend images are pulled on demand, so first use of a new model type incurs a download delay
Verdict Developers who want a private, self-hosted alternative to OpenAI’s platform and need to juggle LLMs, vision, voice, and video without managing a dozen separate services should look here. If you only ever run one small LLM on a single GPU, it is probably overkill.
Frequently asked
- What is mudler/LocalAI?
- LocalAI wraps 36+ inference engines behind one OpenAI-compatible API and pulls them on demand, so you can run LLMs, vision, voice, and video on anything from a CPU to a Jetson.
- Is LocalAI open source?
- Yes — mudler/LocalAI is open source, released under the MIT license.
- What language is LocalAI written in?
- mudler/LocalAI is primarily written in Go.
- How popular is LocalAI?
- mudler/LocalAI has 47.8k stars on GitHub and is currently accelerating.
- Where can I find LocalAI?
- mudler/LocalAI is on GitHub at https://github.com/mudler/LocalAI.