openai/whisper
One transformer handles transcription, translation, and language ID
To give developers a single, general-purpose speech model that handles transcription, translation, and language identification by treating tasks as tokens to predict.
Velocity · 7d
+61
★ / day
Trend
→steady
star history
What it does
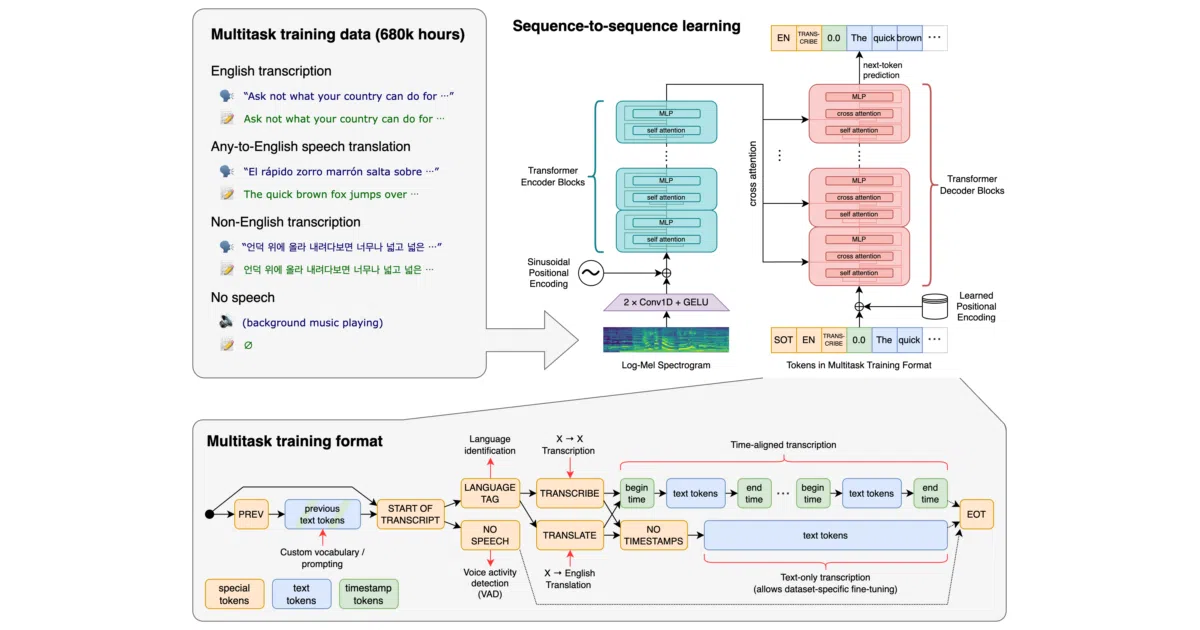
Whisper is a general-purpose speech recognition system built as a Transformer sequence-to-sequence model. It ingests audio and can transcribe speech, translate spoken language into English, identify which language is being spoken, and detect voice activity. The model processes audio in sliding 30-second windows and comes in six sizes, from a 39-million-parameter tiny variant that needs about 1 GB of VRAM to a 1.5-billion-parameter large model requiring roughly 10 GB.
The interesting bit
Instead of chaining separate models into a fragile speech-processing daisy chain, Whisper frames multilingual recognition, translation, language identification, and voice activity detection as a single token-prediction problem. Special tokens act as task specifiers and classification targets, so the decoder learns to route itself based on what you ask for. It is a tidy way to collapse an entire pipeline into one autoregressive model.
Key highlights
- Six model sizes with speed/accuracy tradeoffs; the
turbovariant runs about 8× faster thanlargewith what the project calls minimal accuracy degradation. - English-only variants (
tiny.en,base.en,small.en,medium.en) tend to outperform the multilingual versions for English transcription, especially at the smaller sizes. - Performance varies widely by language; the README publishes WER and CER breakdowns across datasets.
- Code and model weights are released under the MIT License, so the whole stack can run fully offline given sufficient VRAM.
Caveats
- The
turbomodel is explicitly not trained for translation; if you ask it to translate, it will return the original language instead of English. - Real-world inference speed varies significantly depending on language, speaking speed, and available hardware; the published relative speeds were measured on an A100.
- Accuracy differs substantially across languages, so your mileage will vary depending on the target tongue.
Verdict
Developers who want local speech-to-text or offline translation without API billing should look here. If you need predictable real-time streaming on modest hardware, test carefully—the larger models demand up to 10 GB of VRAM and speed swings by language.
Frequently asked
- What is openai/whisper?
- To give developers a single, general-purpose speech model that handles transcription, translation, and language identification by treating tasks as tokens to predict.
- Is whisper open source?
- Yes — openai/whisper is open source, released under the MIT license.
- What language is whisper written in?
- openai/whisper is primarily written in Python.
- How popular is whisper?
- openai/whisper has 105.4k stars on GitHub and is currently holding steady.
- Where can I find whisper?
- openai/whisper is on GitHub at https://github.com/openai/whisper.