01
PrismML-Eng/Bonsai-demo
+57% /wk +168 ★/day↗accelerating
A demo repo for running extreme-quantized language models locally without needing a research cluster.
A demo repo for running extreme-quantized language models locally without needing a research cluster.
It breaks complex tasks across a team of specialized LLM agents that refine their own skills as they work.
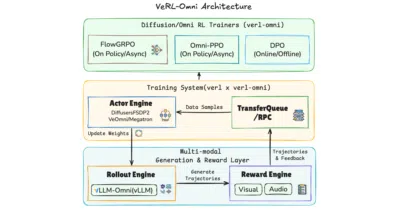
It split off from `verl` to give diffusion, video, and omni-modality models an RL post-training framework that doesn't treat them like chatbots.
TabFM exists so you can run classification and regression on messy, mixed-type tables without retraining a model on your data.
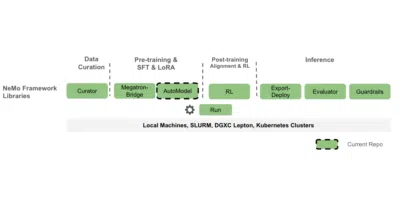
NeMo AutoModel automates the busywork of wiring HuggingFace LLMs and VLMs into PyTorch-native distributed training so you can fine-tune or pretrain without hand-rolling parallelism code.
Xime is a deliberately minimal, Rime-based Android input method that serves as its author's personal testbed for on-device AI experiments in predictive text and speech recognition.
It unifies Stable Diffusion, GGUF chat, Whisper, and Kokoro TTS into a single offline desktop GUI so you can skip cloud APIs, subscriptions, and censorship filters.
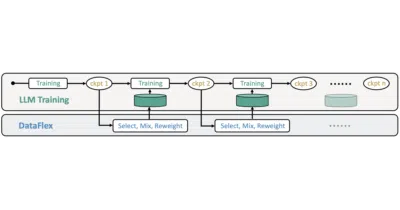
DataFlex stops LLM training loops from wasting compute on static data mixes by dynamically selecting, mixing, and reweighting samples inside LLaMA-Factory.
It turns your local machine into an OpenAI-compatible inference endpoint so agents and IDEs can run on offline models without reconfiguration.
Uses multimodal LLMs to transcribe PDFs into Markdown, preserving complex layouts that traditional extractors mangle.
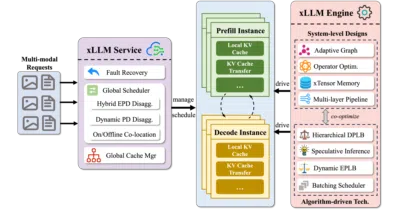
xLLM is a C++ inference framework specifically optimized for Chinese AI accelerators, and it already powers JD.com’s core retail production workloads.
Curated technical deep-dives covering everything from NVLink signal integrity to Kubernetes GPU scheduling and Huawei NPU porting.
This Go CLI turns a single sentence into a full novel by making Architect, Writer, and Editor LLM agents plan, draft, and review inside a long-loop state machine—no human hand-holding required.
Turns Grok's web interface into a standard API so your existing tools just work.
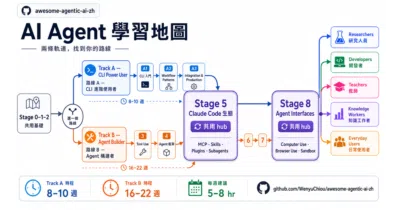
It turns the scattered firehose of agentic AI tools into an 8-stage curriculum with homework and realistic time budgets.
Built to prove that hand-written Rust kernels and no framework runtime can serve frontier models without the bloat.
It exists to run a small army of speech-to-text models through a single GGUF-based ggml runtime that actually checks its math.
An AI companion platform that remembers, feels, and stares at your screen—now with a Steam release and a 1000-year SSL certificate.
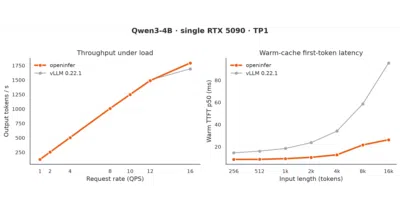
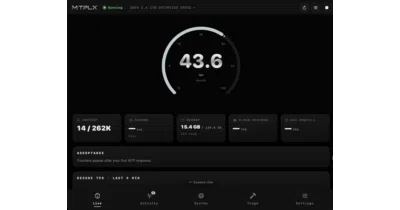
MTPLX squeezes extra tokens per second out of Apple Silicon by using the multi-token prediction heads that ship with modern models like Qwen 3.6, instead of leaving them idle like most runtimes.
AutoFlow turns documentation into a conversational knowledge graph, then lets you embed the chat window anywhere.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.