01
diegosouzapw/OmniRoute
+1543 ★/day↗accelerating
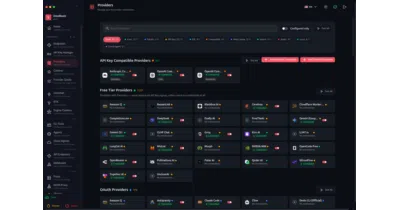
OmniRoute keeps your coding agents online by automatically failing over across 177 AI providers—including free tiers—when quotas run dry.
OmniRoute keeps your coding agents online by automatically failing over across 177 AI providers—including free tiers—when quotas run dry.
Pi bundles a unified LLM API, agent runtime, and interactive coding CLI into a monorepo that treats every dependency update as a potential attack.
Sub2API pools AI subscriptions behind a metered gateway so teams or resellers can distribute API quotas without building their own billing stack.
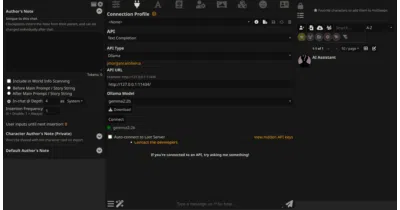
A Go proxy that handles OAuth login for Claude Code and Codex so you can call them through standard API clients.
9Router is a local proxy that auto-switches your AI coding tools from paid to free providers and compresses token-heavy tool outputs so you stop hitting limits.
It exists because clicking 'generate' isn't enough when you need to control every model, parameter, and preprocessing step.
It catalogs legitimate services offering free API access to large language models, complete with rate limits, model lists, and data-privacy caveats.
Because juggling native APIs from a dozen LLM vendors, each with its own auth and billing, is a recipe for migraines.
Because swapping from GPT-4o to Claude shouldn't require rewriting your request plumbing.
It exists to run large language models on virtually any hardware—from Apple Silicon to RISC-V to your browser—with zero external dependencies and minimal setup.
vLLM is an open-source inference engine that pages attention key-value memory like an operating system to drive higher GPU throughput, then exposes it through an OpenAI-compatible API.
It wraps local inference and fine-tuning for open models in a web UI, using custom kernels to squeeze more performance out of desktop GPUs than standard tooling.
It exists so you can download, run, and chat with open-weight LLMs locally through one CLI and REST API, keeping inference on your own silicon.
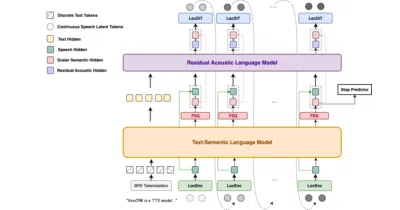
VoxCPM2 proves TTS doesn't need discrete tokens: a 2B-parameter diffusion model generates continuous 48kHz speech for 30 languages and text-prompted voice cloning.
A minimal C/C++ port of OpenAI’s Whisper built to transcribe speech locally on phones, browsers, and underclocked POWER9 boxes.
AirLLM slices giant transformers into layer shards so they fit in consumer VRAM without quantization or distillation.
LibreChat bundles every major LLM provider into a single self-hosted chat platform so teams don't have to choose—or leak data.
SillyTavern gives AI hobbyists a single, local interface to command text generators, image engines, and voice models across dozens of backends without losing control of their prompts or data.
It centralizes model definitions so the same architecture works across PyTorch, JAX, vLLM, and llama.cpp without rewrites.
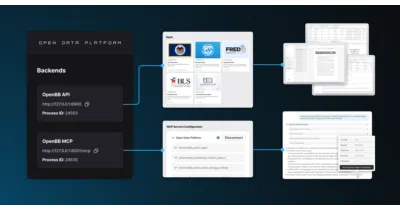
OpenBB normalizes proprietary and public financial data so engineers can feed the same sources to Python scripts, REST APIs, Excel, and AI agents without rebuilding integrations.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.