lyogavin/airllm
70B models on a 4GB GPU, no magic tricks required
AirLLM slices giant transformers into layer shards so they fit in consumer VRAM without quantization or distillation.
Velocity · 7d
+177
★ / day
Trend
↗accelerating
star history
What it does
AirLLM is a Python inference wrapper that decomposes large Hugging Face models into per-layer shards, loading and unloading each layer on demand during generation. The README claims this lets you run Llama-2 70B on a single 4GB GPU, and Llama-3.1 405B on 8GB VRAM, without requiring quantization, distillation, or pruning. It wraps common transformers patterns so the API looks familiar: AutoModel.from_pretrained() followed by standard .generate().
The interesting bit
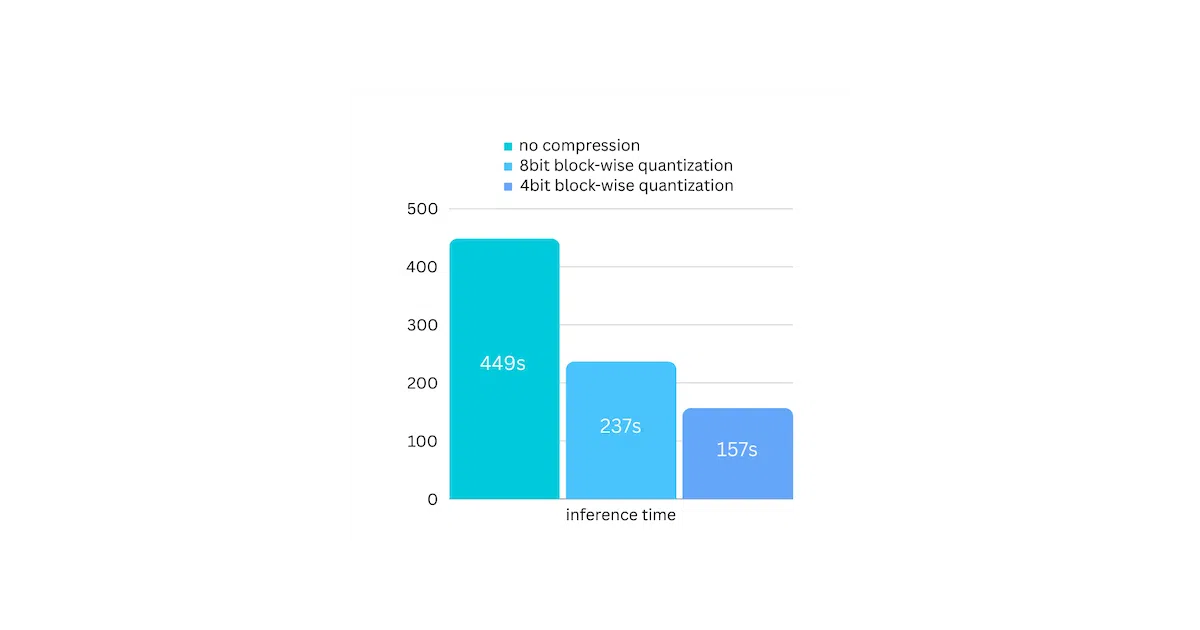
The trick is treating disk bandwidth as cheaper than GPU memory. By keeping only one layer resident at a time and prefetching the next, AirLLM trades throughput for capacity. The project also adds optional block-wise weight quantization (4-bit or 8-bit) to shrink the shard files and claims up to 3× speedup, though the baseline is the unoptimized layer-by-layer path, not a fully loaded model.
Key highlights
- Supports a wide zoo of model families: Llama, Mistral, Mixtral, Qwen, ChatGLM, Baichuan, InternLM, and others.
- Runs on Apple Silicon Macs via MLX, and now supports CPU inference as of v2.10.
AutoModelclass auto-detects model architecture, so you don’t need to pick a specific wrapper.- Optional
delete_originalflag to purge the full downloaded model and keep only the split shards, saving disk space. - Claims 10% speed improvement from prefetching overlaps, though only the Llama2 wrapper supports this currently.
Caveats
- The layer-splitting process is “very disk-consuming”; the FAQ warns that
MetadataIncompleteBuffererrors almost always mean you ran out of disk space. - Prefetching is currently limited to the Llama2-specific class, not the generic
AutoModel. - The 3× speedup claim applies to the compressed path versus the uncompressed layer-shard path; it is not a comparison against standard vLLM or
acceleratebig-model inference.
Verdict
Worth a look if you have a small GPU, plenty of disk, and patience. If you care about tokens-per-second or already own an A100, this is the wrong tool.
Frequently asked
- What is lyogavin/airllm?
- AirLLM slices giant transformers into layer shards so they fit in consumer VRAM without quantization or distillation.
- Is airllm open source?
- Yes — lyogavin/airllm is open source, released under the Apache-2.0 license.
- What language is airllm written in?
- lyogavin/airllm is primarily written in Jupyter Notebook.
- How popular is airllm?
- lyogavin/airllm has 23.9k stars on GitHub and is currently accelerating.
- Where can I find airllm?
- lyogavin/airllm is on GitHub at https://github.com/lyogavin/airllm.