01
pewdiepie-archdaemon/odysseus
+8238 ★/day→steady
A self-hosted AI workspace that bolts chat, agents, email triage, calendars, and deep research onto your own hardware.
A self-hosted AI workspace that bolts chat, agents, email triage, calendars, and deep research onto your own hardware.
A deliberately narrow inference engine that treats your SSD as first-class KV cache real estate.
Karpathy's minimal LLM training harness turns a $43K 2019 training run into a sub-$100 afternoon project.
The pi project bundles a CLI coding agent with an unusually paranoid approach to supply-chain security.
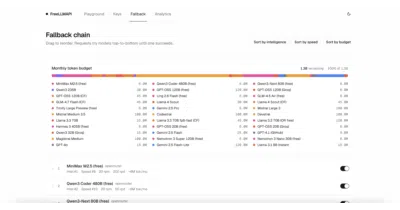
A local proxy that turns sixteen scattered LLM free tiers into one OpenAI-compatible endpoint with automatic failover.
A massive Mixture-of-Experts model that trains cheap and runs lean by keeping most of its weights asleep.
Because Google's free web chat doesn't have an official API, so someone built the unofficial one by reverse-engineering its private protocol.
OpenFang ships autonomous "Hands"—pre-built agents that research, monitor, and publish on schedules, not chat prompts.
An open-source gateway for splitting AI subscriptions across teams without breaking native tools.
Ollama wraps llama.cpp in a one-line installer and a model registry so you can run open weights without reading a dozen READMEs.
oMLX brings vLLM-style continuous batching and tiered KV caching to Apple Silicon, controlled from a native Swift menubar app.
OpenSquilla routes each turn to the cheapest capable LLM, keeping persistent memory and tool use identical across CLI, Web UI, and chat channels.
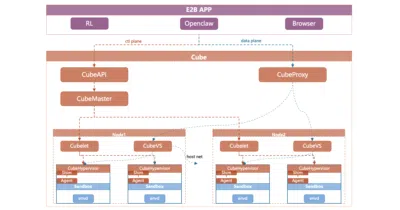
A Rust-based sandbox service that swaps container speed for real kernel isolation while keeping the same Python SDK.
Local proxy that auto-falls back to free models when your paid quota dies mid-session.
A Gradio-based web UI that crams every community trick for image generation into one browser tab.
A Rust vector index that squeezes 31 GB of float32 embeddings into 4 GB without a training phase, then outruns FAISS on the query.
A Go proxy that exposes Gemini CLI, Claude Code, Codex, and Grok through standard OpenAI-compatible APIs—no API keys required, just your existing OAuth logins.
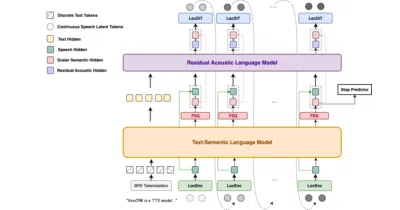
VoxCPM2 generates speech directly from text using continuous diffusion, no discrete audio tokens required.
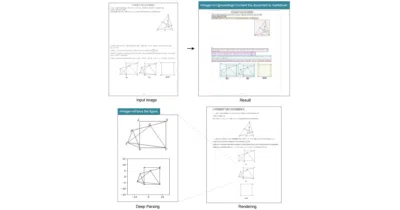
An LLM-centric vision encoder that squeezes documents into surprisingly few tokens, then lets the language model do the actual reading.
A dependency-free C/C++ inference engine that squeezes large language models onto laptops, phones, and browsers through aggressive quantization and hand-rolled kernels.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.