tashfeenahmed/freellmapi
Sixteen free LLM tiers, one OpenAI-shaped funnel
It aggregates the free tiers of sixteen LLM providers into one OpenAI-compatible endpoint so you can experiment without juggling rate limits.
Velocity · 7d
+73
★ / day
Trend
↘cooling
star history
What it does
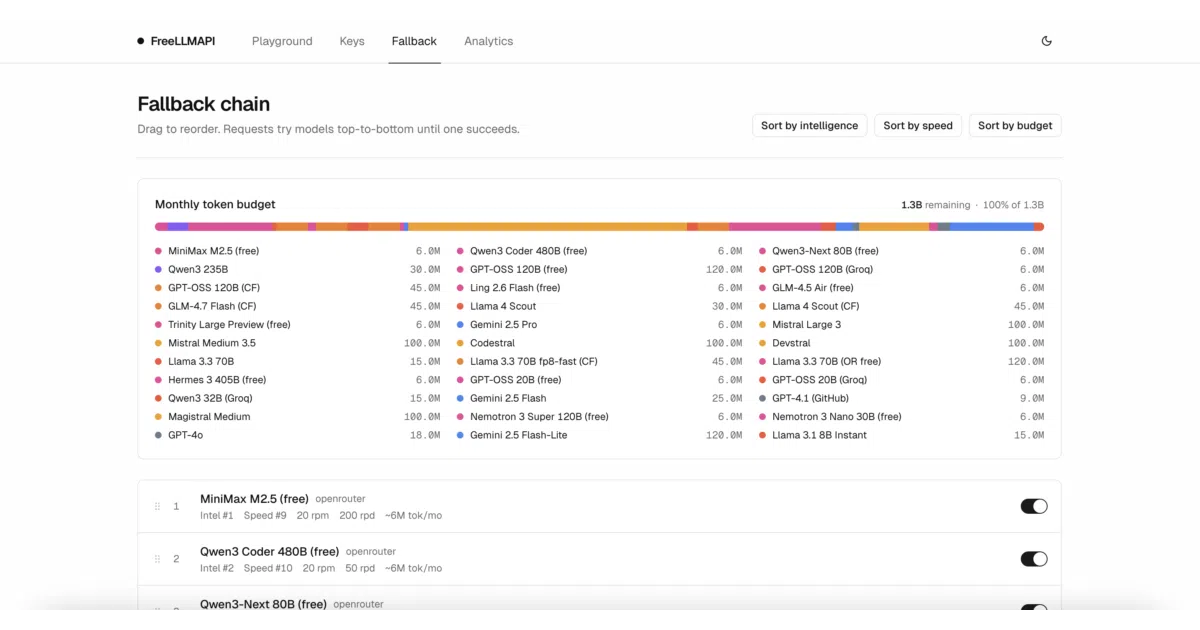
FreeLLMAPI is a self-hosted proxy that sits between your OpenAI-compatible client and sixteen different LLM providers. It exposes a single /v1/chat/completions endpoint, routes each request to whichever provider still has free-tier headroom, and automatically fails over if you hit a rate limit, timeout, or 5xx. Your upstream keys are encrypted at rest in SQLite, and the whole thing runs on a Raspberry Pi if you want.
The interesting bit
The router tracks per-key usage—RPM, RPD, TPM, TPD—so it knows exactly which key is about to hit its cap before it sends the request. It also pins multi-turn conversations to the same model for thirty minutes, which is the kind of paranoid attention to detail you need when your backend is a patchwork of someone else’s free tiers.
Key highlights
- Aggregates roughly 1.7 billion tokens per month across 100+ models from Google, Groq, Cerebras, SambaNova, Mistral, OpenRouter, GitHub Models, Cloudflare, Cohere, HuggingFace, Z.ai, Ollama, Kilo, Pollinations, LLM7, and NVIDIA (disabled by default), plus any custom OpenAI-compatible endpoint.
- Implements both chat completions and the newer Responses API shim that Codex CLI expects, with full streaming and tool-call round-tripping.
- Falls back up to twenty times through a user-ordered provider chain when a key returns 429, 5xx, or times out.
- Single unified API key for all your apps; upstream provider keys never leave the server.
- ~40 MB RSS at idle on Node 20+; multi-arch Docker images including ARM64.
Caveats
- Explicitly single-user by design: no multi-tenant auth, no per-user billing, and the authors mark it for personal experimentation only.
- No support for embeddings, image generation, audio, legacy completions, moderation, or multiple completions per request (
n > 1). - Some providers (Kilo, Pollinations, LLM7) work anonymously, but most require you to bring your own free-tier key.
Verdict
Grab this if you are a solo developer, tinkerer, or hobbyist who wants to experiment across dozens of models without managing sixteen dashboards. Skip it if you need team billing, SLA guarantees, or anything beyond chat completions and tool calling.
Frequently asked
- What is tashfeenahmed/freellmapi?
- It aggregates the free tiers of sixteen LLM providers into one OpenAI-compatible endpoint so you can experiment without juggling rate limits.
- Is freellmapi open source?
- Yes — tashfeenahmed/freellmapi is open source, released under the MIT license.
- What language is freellmapi written in?
- tashfeenahmed/freellmapi is primarily written in TypeScript.
- How popular is freellmapi?
- tashfeenahmed/freellmapi has 16.6k stars on GitHub and is currently cooling off.
- Where can I find freellmapi?
- tashfeenahmed/freellmapi is on GitHub at https://github.com/tashfeenahmed/freellmapi.