deepseek-ai/DeepSeek-OCR
Squeezing documents into 64-token thumbnails for LLMs
An OCR model that asks how few vision tokens an LLM needs before it can no longer read the page.
Velocity · 7d
+8.4
★ / day
Trend
→steady
star history
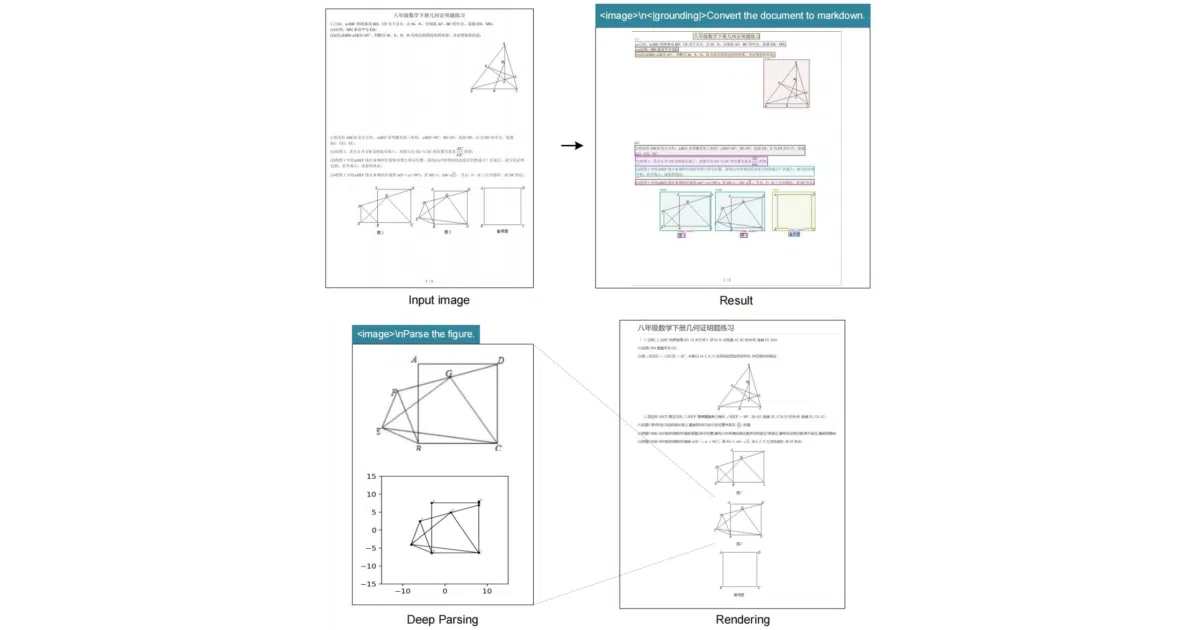
What it does DeepSeek-OCR reads text, figures, and layouts from images and PDFs, then emits structured text such as Markdown or plain OCR output. It maps every input to a tight vision-token budget—between 64 tokens for a 512×512 image and 400 tokens for 1280×1280—operating on the premise that an LLM only needs a compressed sketch of the page, not a photographic embedding.
The interesting bit The project frames the vision encoder as a compression problem, asking how few tokens an LLM needs to comprehend a page rather than see it in high fidelity. It also enforces structural correctness at decode time through a custom vLLM logits processor that can whitelist specific token IDs—such as table cell tags—to keep generated markup syntactically valid.
Key highlights
- Four fixed resolution modes plus a dynamic “Gundam” mode that tiles images as n×640×640 crops plus one 1024×1024 anchor.
- Vision-token budgets are aggressively low: 64 to 400 tokens, depending on the chosen resolution tier.
- Custom
NGramPerReqLogitsProcessorfor vLLM supports token whitelisting to constrain outputs like table HTML. - Supports task-specific prompts for document-to-Markdown conversion, figure parsing, reference grounding, and general description.
- The README claims PDF inference reaches roughly 2,500 tokens/s on an A100-40GB.
Caveats
- Loading via Transformers requires
trust_remote_code=True, and the documented environment is pinned to CUDA 11.8 with PyTorch 2.6.0. - Upstream vLLM integration currently depends on nightly builds, and the README warns about version conflicts between vLLM and Transformers.
- A successor model, DeepSeek-OCR2, is already referenced in the release notes with a 2026 date, so the timeline may be aspirational or typo-ridden.
Verdict Useful if you are building document pipelines where token economy and throughput matter more than photographic visual reasoning. Look elsewhere if you need a general vision model that treats images as scenes rather than text containers.
Frequently asked
- What is deepseek-ai/DeepSeek-OCR?
- An OCR model that asks how few vision tokens an LLM needs before it can no longer read the page.
- Is DeepSeek-OCR open source?
- Yes — deepseek-ai/DeepSeek-OCR is open source, released under the MIT license.
- What language is DeepSeek-OCR written in?
- deepseek-ai/DeepSeek-OCR is primarily written in Python.
- How popular is DeepSeek-OCR?
- deepseek-ai/DeepSeek-OCR has 23.6k stars on GitHub and is currently holding steady.
- Where can I find DeepSeek-OCR?
- deepseek-ai/DeepSeek-OCR is on GitHub at https://github.com/deepseek-ai/DeepSeek-OCR.