OpenBMB/VoxCPM
Tokenizer-free TTS that dreams up voices from text prompts
VoxCPM2 proves TTS doesn't need discrete tokens: a 2B-parameter diffusion model generates continuous 48kHz speech for 30 languages and text-prompted voice cloning.
Velocity · 7d
+85
★ / day
Trend
↗accelerating
star history
What it does
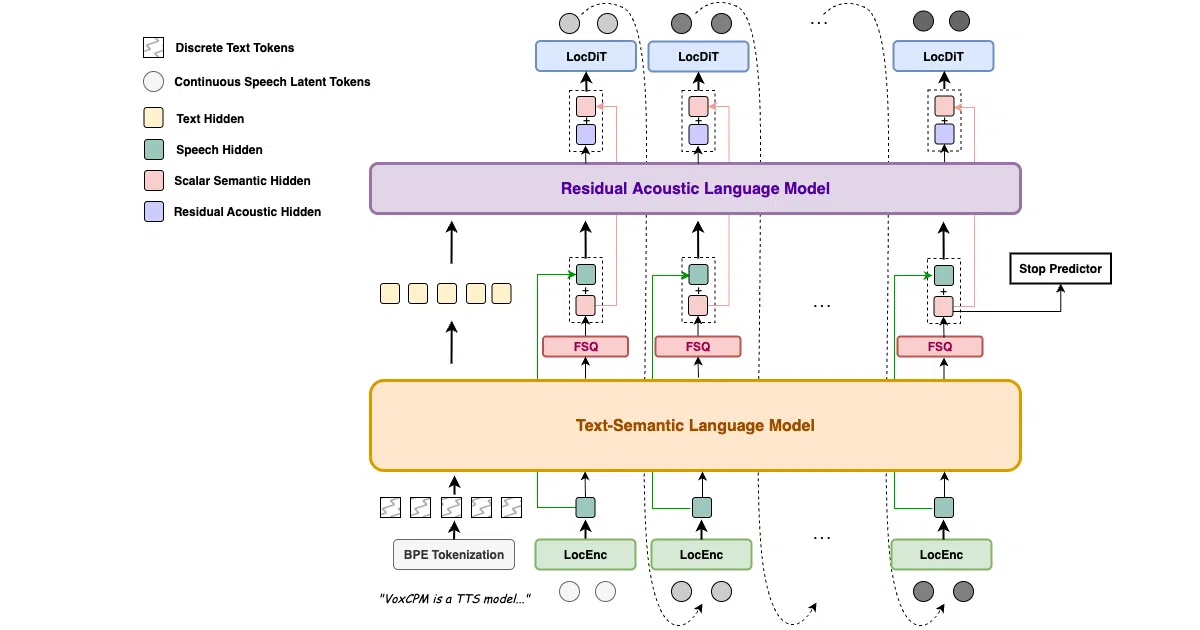
VoxCPM2 is a 2-billion-parameter text-to-speech model built on the MiniCPM-4 backbone and trained on over 2 million hours of multilingual speech data. It takes text input in any of 30 supported languages and outputs 48kHz studio-quality audio without relying on discrete speech tokens. The system can invent a voice from a natural-language description, clone a voice from a short audio reference with optional style controls, or perform Ultimate Cloning by continuing from a reference audio plus its transcript to preserve timbre, rhythm, and emotion.
The interesting bit
Instead of compressing speech into discrete tokens like most modern TTS pipelines, VoxCPM2 uses an end-to-end diffusion autoregressive architecture to generate continuous speech representations directly. It also upsamples internally: it accepts 16kHz reference audio but outputs 48kHz through an asymmetric AudioVAE V2 encode/decode design, so it doesn’t need an external super-resolution model.
Key highlights
- 30-language multilingual synthesis with no language tag required, plus several Chinese dialects
Voice Design: create a new speaker identity from a text description without reference audioControllable Cloning: clone timbre from a short clip while steering emotion, pace, and expression via text prompts- Real-time streaming with RTF around
0.3on an RTX 4090, dropping to roughly0.13when served throughNano-vLLMorvLLM-Omniwith PagedAttention - Apache-2.0 licensed weights and code, explicitly cleared for commercial use, with an OpenAI-compatible
/v1/audio/speechendpoint available viavLLM-Omni
Caveats
- Requires Python 3.10–3.12, PyTorch ≥ 2.5.0, and CUDA ≥ 12.0, so environment constraints are fairly specific
- The
Ultimate Cloningmode demands an exact transcript of the reference audio, which adds preparation overhead vLLM-Omniintegration is noted as “rapidly evolving” in the documentation
Verdict
Developers building multilingual voice applications or commercial audio pipelines should evaluate this, especially given the Apache-2.0 license and OpenAI-compatible serving options. Those on older CUDA stacks or who need turnkey edge deployment should check the hardware requirements carefully.
Frequently asked
- What is OpenBMB/VoxCPM?
- VoxCPM2 proves TTS doesn't need discrete tokens: a 2B-parameter diffusion model generates continuous 48kHz speech for 30 languages and text-prompted voice cloning.
- Is VoxCPM open source?
- Yes — OpenBMB/VoxCPM is open source, released under the Apache-2.0 license.
- What language is VoxCPM written in?
- OpenBMB/VoxCPM is primarily written in Python.
- How popular is VoxCPM?
- OpenBMB/VoxCPM has 34k stars on GitHub and is currently accelerating.
- Where can I find VoxCPM?
- OpenBMB/VoxCPM is on GitHub at https://github.com/OpenBMB/VoxCPM.