01
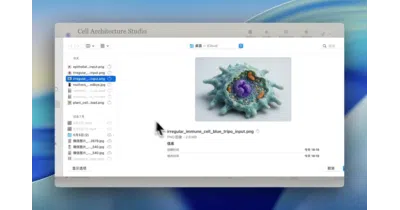
helloianneo/ian-xiaohei-illustrations
+303 ★/day→steady
This Codex Skill turns Chinese articles into hand-drawn, slightly absurd 16:9 illustrations where a deadpan black blob does the conceptual heavy lifting.
This Codex Skill turns Chinese articles into hand-drawn, slightly absurd 16:9 illustrations where a deadpan black blob does the conceptual heavy lifting.
Curated prompts and API patterns for OpenAI's GPT-Image-2, organized by real use case rather than vibe or aesthetic.
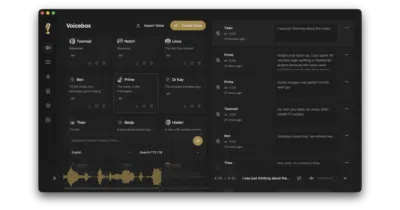
Voicebox bundles seven TTS engines, Whisper dictation, and MCP agent hooks into a single Tauri app — all offline.
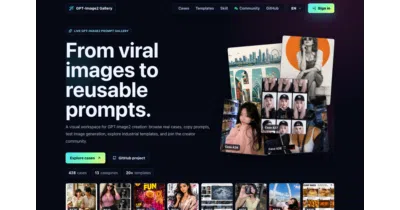
A crowdsourced library that reverse-engineers GPT-Image2 examples into structured, reusable prompt templates for automation workflows.
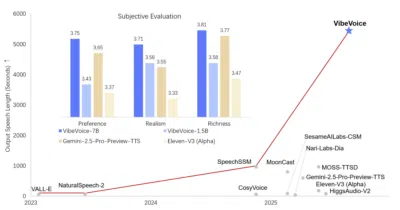
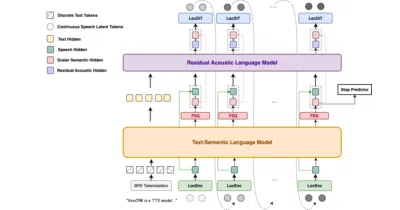
A research family of ASR and TTS models built on the bet that voice should be processed as long-form narrative, not chopped into seconds-long shards.
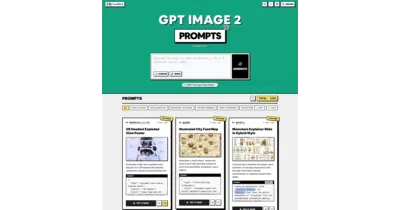
A curated, multilingual prompt library for OpenAI's GPT Image 2, with preview images and Raycast snippet support.
MisoTTS brings Sesame-style conversational speech synthesis to local hardware, with a Llama backbone and a stubbornly English-only vocabulary.
OmniVoice Studio runs voice cloning, dubbing, and dictation locally on macOS, Windows, and Linux — no API keys, no cloud, no subscription.
A Gradio-based web UI that crams every community trick for image generation into one browser tab.
A TypeScript skillset that turns a single photo into meshes, gaussian splats, and sound effects by orchestrating multiple generative models through Claude.
VoxCPM2 generates speech directly from text using continuous diffusion, no discrete audio tokens required.
Pixelle-Video wires LLMs, image/video generators, TTS engines, and ffmpeg into a single Streamlit app that spits out short-form videos from a topic string.
React prototype that wires multiple image-to-3D APIs into a single presentation-ready studio.
A solo-built TypeScript studio that turns Chinese web novels into AI-generated storyboards, characters, and voiced video.
Outpainting is the appetizer; the main course is automated 2D game asset generation with seam-aware tooling that exports engine-ready packs.
Deep-Live-Cam swaps faces in real time using a single source image and your laptop camera.
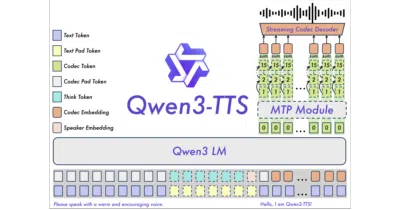
A 1.7B-parameter speech model that streams its first audio packet after a single character and takes voice design instructions in plain English—or Chinese, or nine other languages.
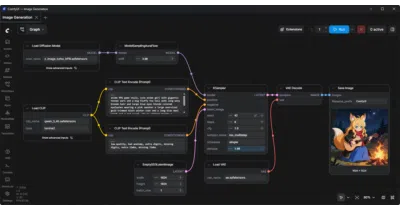
A visual programming interface for image, video, 3D, and audio generation that treats model pipelines as composable graphs.
A TypeScript stack that automates scriptwriting, storyboarding, and video synthesis for the short-drama gold rush.
A community-curated gallery showing off the weird, useful, and surprisingly specific tricks possible with Gemini-2.5-flash-image.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.