deepseek-ai/DeepSeek-V3
A 671B-parameter MoE trained on under 2.8M GPU hours
DeepSeek-V3 exists to prove that a 671-billion-parameter model can train end-to-end without a single rollback, activate only 37B parameters per token, and still match leading closed-source systems.
Velocity · 7d
+6.7
★ / day
Trend
→steady
star history
What it does
DeepSeek-V3 is a 671-billion-parameter Mixture-of-Experts language model that activates only 37 billion parameters per token. It was pre-trained on 14.8 trillion tokens, then fine-tuned and distilled from the long-chain-of-thought model DeepSeek-R1. The repository hosts model weights, benchmark results, and architectural documentation for a system the authors say outperforms other open-source models and matches leading closed-source ones.
The interesting bit
The training efficiency claims are the real eyebrow-raiser: the full run consumed just 2.788 million H800 GPU hours, and the authors report no irrecoverable loss spikes or rollbacks. They pulled this off with an FP8 mixed-precision framework and by co-designing algorithms, frameworks, and hardware to nearly eliminate cross-node communication bottlenecks in MoE training. An auxiliary-loss-free load-balancing strategy and a multi-token prediction objective are the architectural novelties meant to keep quality from degrading at scale.
Key highlights
- 671B total parameters with 37B activated per token; 128K context window
- Pre-training took ~2.664M H800 GPU hours; subsequent stages added only ~0.1M
- FP8 mixed-precision training validated at extreme scale, according to the project
- Reasoning capabilities distilled from DeepSeek-R1’s long-CoT patterns into standard LLM outputs
- Multi-Token Prediction module weights included (14B parameters) for speculative decoding, though community support is still maturing
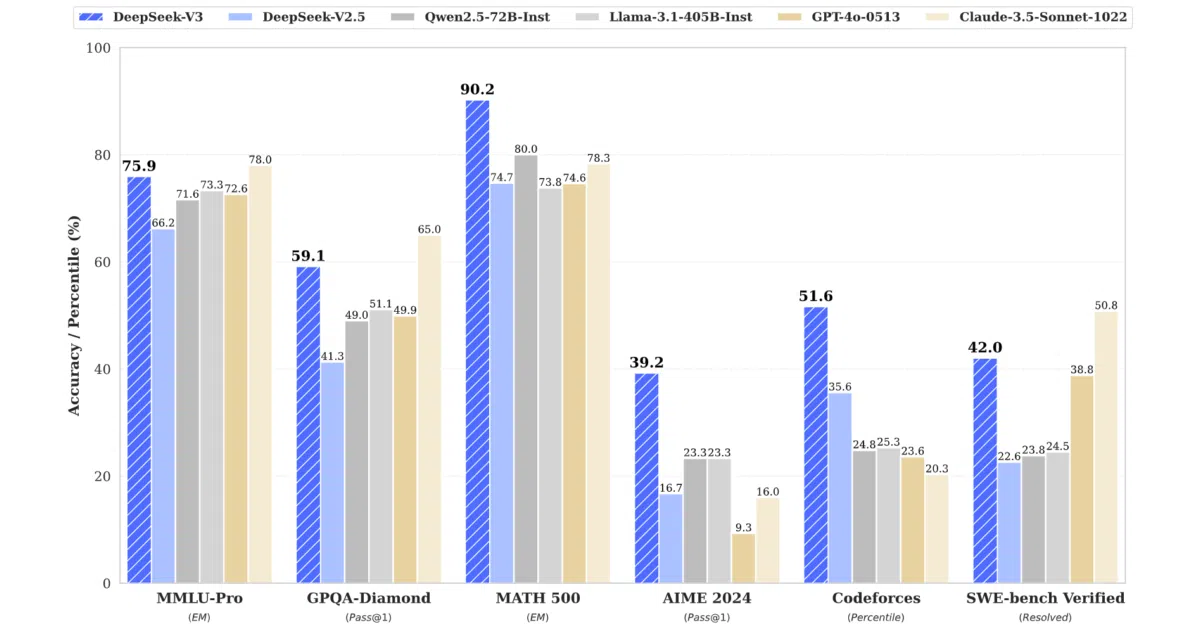
- Evaluation tables pit it against Qwen2.5 72B, LLaMA 3.1 405B, Claude-3.5 Sonnet, and GPT-4o
Caveats
- The repository is mainly model weights and results, not a reusable training framework
- Multi-Token Prediction support is noted as “under active development within the community”
- Model weights fall under a separate Model Agreement license, distinct from the MIT-licensed code
Verdict
Study this if you are researching efficient MoE training or need a capable open-weight model for math and code. Look elsewhere if you want a small, easy-to-finetune model or a fully open training stack.
Frequently asked
- What is deepseek-ai/DeepSeek-V3?
- DeepSeek-V3 exists to prove that a 671-billion-parameter model can train end-to-end without a single rollback, activate only 37B parameters per token, and still match leading closed-source systems.
- Is DeepSeek-V3 open source?
- Yes — deepseek-ai/DeepSeek-V3 is open source, released under the MIT license.
- What language is DeepSeek-V3 written in?
- deepseek-ai/DeepSeek-V3 is primarily written in Python.
- How popular is DeepSeek-V3?
- deepseek-ai/DeepSeek-V3 has 104k stars on GitHub and is currently holding steady.
- Where can I find DeepSeek-V3?
- deepseek-ai/DeepSeek-V3 is on GitHub at https://github.com/deepseek-ai/DeepSeek-V3.