diegosouzapw/OmniRoute
One endpoint, 177 backends, and a serious free-tier habit
OmniRoute keeps your coding agents online by automatically failing over across 177 AI providers—including free tiers—when quotas run dry.
Feature · 23 Jul 2026
Inside the Gateway That Compresses Prompts and Chains Free AI
OmniRoute unifies 177 LLM providers behind a single local endpoint, stacking prompt compression with cascading fallbacks to keep coding agents running on free tiers.
Read the in-depth article →
Velocity · 7d
+1088
★ / day
Trend
↗accelerating
star history
What it does
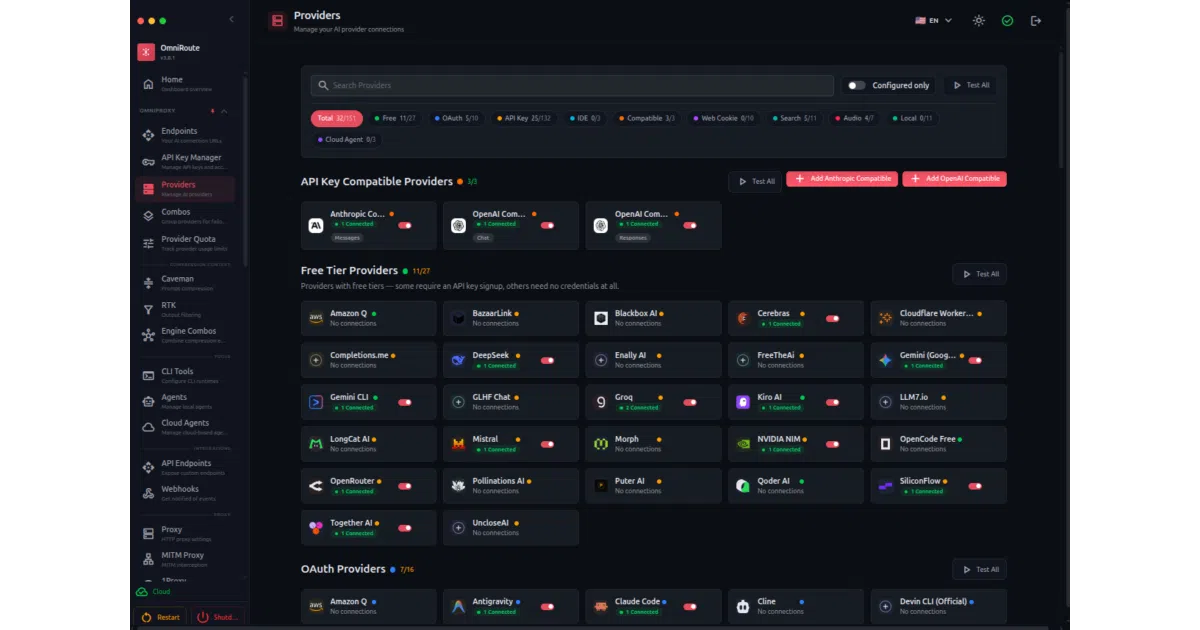
OmniRoute sits between your IDE or CLI and a long roster of AI providers. You point tools like Claude Code, Cursor, or Copilot at a single local /v1 endpoint, and it translates requests across OpenAI, Claude, Gemini, and Responses API formats. When a provider hits a rate limit or your subscription quota empties, it silently shifts traffic to the next backend in milliseconds.
The interesting bit
The “combo” system is the clever part: you define a chain of models (or just set auto) and OmniRoute treats it as a priority queue, sliding down from paid subscriptions to API keys to cheap providers to free forever tiers like Kiro and Pollinations. It also runs RTK plus Caveman stacked compression to shrink tool-heavy context like git diff and logs, claiming an average ~89% token reduction on eligible sessions.
Key highlights
- 177 integrated providers, 50+ with free tiers and 11 advertised as free forever
- 14 routing strategies including round-robin, cost-optimized, and least-used
- 4-tier auto-fallback: Subscription → API key → Cheap → Free
- MCP (37 tools), A2A support, circuit breakers, TLS fingerprint stealth, and 4,690+ tests
- Desktop app, PWA, Docker image, and npm package for local-first deployment
Caveats
- Token compression savings (15–95%) are self-reported figures with no independent benchmarks shown in the README
- Credential storage and encryption specifics are not described beyond the general “local-first” claim
Verdict
Worth a look if you juggle multiple AI subscriptions and want your coding agents to survive quota outages without manual key-swapping. Skip it if you need a managed, enterprise-audited gateway with published security whitepapers.
Frequently asked
- What is diegosouzapw/OmniRoute?
- OmniRoute keeps your coding agents online by automatically failing over across 177 AI providers—including free tiers—when quotas run dry.
- Is OmniRoute open source?
- Yes — diegosouzapw/OmniRoute is open source, released under the MIT license.
- What language is OmniRoute written in?
- diegosouzapw/OmniRoute is primarily written in TypeScript.
- How popular is OmniRoute?
- diegosouzapw/OmniRoute has 25.4k stars on GitHub and is currently accelerating.
- Where can I find OmniRoute?
- diegosouzapw/OmniRoute is on GitHub at https://github.com/diegosouzapw/OmniRoute.