01
ruvnet/RuView
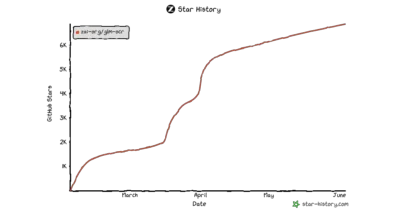
+196 ★/day→steady
A $9 ESP32 board turns radio reflections into room-scale presence detection, vital signs, and pose estimation — no lenses, no wearables, no cloud.
A $9 ESP32 board turns radio reflections into room-scale presence detection, vital signs, and pose estimation — no lenses, no wearables, no cloud.
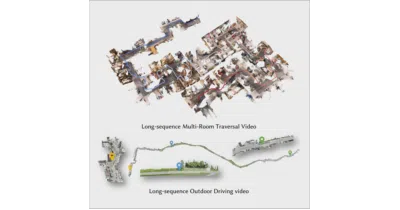
LingBot-Map reconstructs scenes from streaming video in one forward pass, handling 10,000+ frames without iterative optimization.
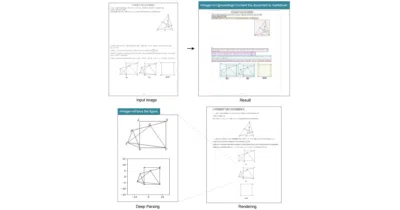
An LLM-centric vision encoder that squeezes documents into surprisingly few tokens, then lets the language model do the actual reading.
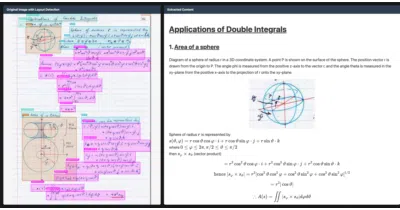
GLM-OCR squeezes document understanding into a sub-1B model with a layout-aware pipeline and enough deployment options to please any ops team.
Chandra OCR 2 turns scanned chaos into structured Markdown, HTML, or JSON without destroying the layout.
A Python toolkit that reverse-engineers alpha-blended logos, strips C2PA manifests, and diffuses away invisible fingerprints like SynthID.
SAM lets you isolate any object in an image with a click or bounding box, no custom training required.
Ultralytics turned the classic object detector into a unified computer-vision Swiss Army knife you can train via CLI or Python.
OmniParser extracts clickable elements from raw screenshots so vision models can actually *do* things on a desktop without peeking at the DOM.
DINOv3 is a family of self-supervised vision backbones designed to produce high-quality dense features for everything from semantic segmentation to satellite canopy mapping, often beating task-specialized models out of the box.
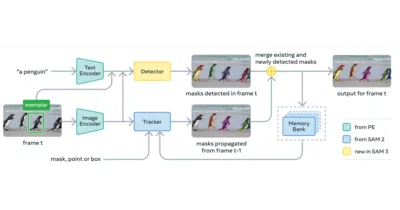
A foundation model that segments images and videos using open-vocabulary text prompts like "a player in white."
PaddleOCR turns scans and PDFs into structured Markdown or JSON using a tiny vision-language model that punches above its weight class.
Upscayl wraps Real-ESRGAN and Vulkan in an Electron app so you can enlarge images without paying Topaz Gigapixel's rent.
A model-agnostic Python toolkit that handles the boring parts of computer vision: annotations, dataset juggling, and tracking.
A single small vision-language model that parses documents, charts, and even street signs into structured text or SVG code.
VGGT turns one image—or a hundred—into camera poses, depth maps, point clouds, and trackable 3D points without any optimization loop.
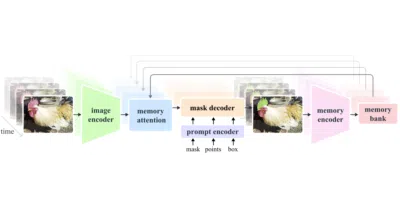
SAM 2 extends the original Segment Anything to video with streaming memory, turning one-off image masks into persistent object tracking.
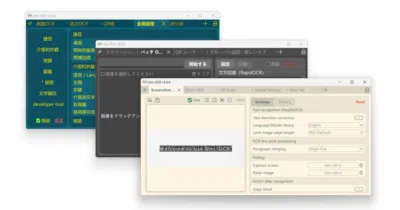
A Qt-based desktop app for screenshot, batch, and PDF OCR without phoning home to any API.
A Python toolkit for face manipulation built around job queues, remixable steps, and headless automation rather than one-off GUI wizardry.
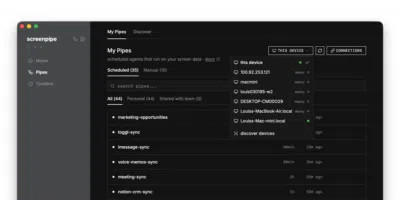
screenpipe records everything you see, say, and hear—locally, searchable, and feedable to AI agents.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.