facebookresearch/vggt
A transformer that builds 3D scenes from one photo—or hundreds
VGGT replaces the traditional multi-stage 3D reconstruction pipeline with a single feed-forward model that predicts cameras, depth, and geometry from one or many images in seconds.
Velocity · 7d
+17
★ / day
Trend
→steady
star history
What it does
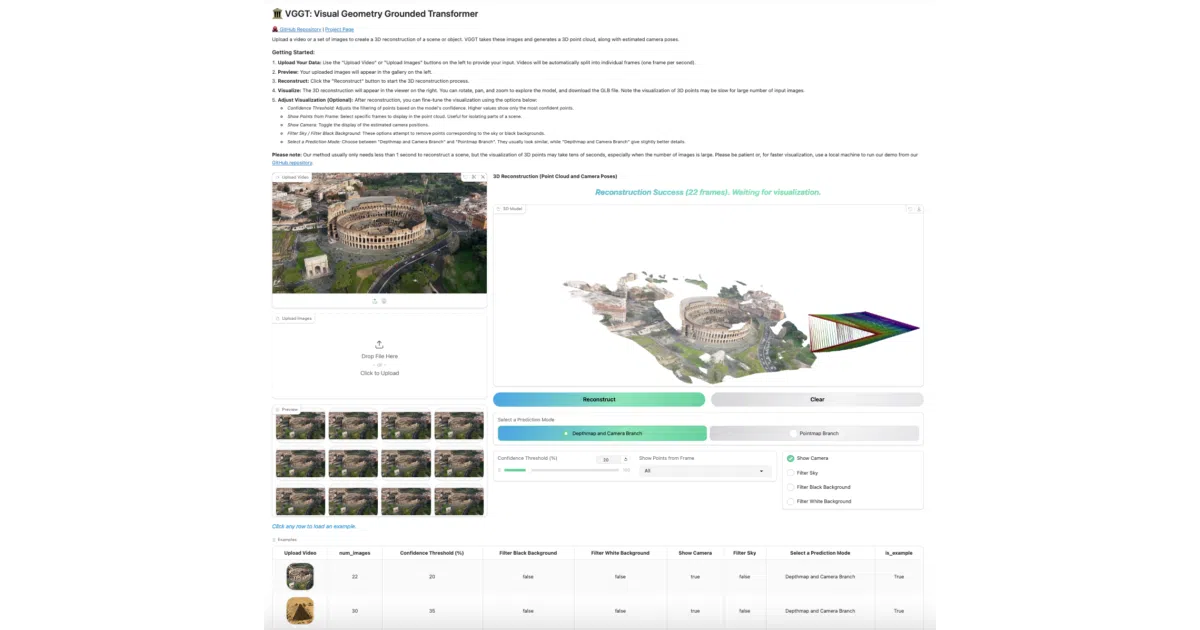
VGGT is a feed-forward transformer that takes one or more images and predicts the full 3D structure of the scene: camera poses, intrinsics, depth maps, point maps, and 3D point tracks. It runs in under a second and can export results directly to COLMAP format for use with Gaussian splatting tools like gsplat. The model also handles single-image reconstruction zero-shot, despite never being trained specifically for monocular tasks.
The interesting bit
Instead of chaining together feature matching, structure-from-motion, and multi-view stereo, VGGT infers everything in a single forward pass. That makes it less a traditional pipeline and more a vision foundation model for geometry.
Key highlights
- CVPR 2025 Best Paper Award
- Predicts extrinsics, intrinsics, depth, point maps, and tracks from 1 to hundreds of views
- Reconstructs in less than one second (visualization overhead is separate)
- Exports to
COLMAPfor direct integration with NeRF and Gaussian splatting workflows - Training code and fine-tuning examples are available in the repository
- A separate commercial-use checkpoint exists, though it requires an automated application workflow similar to LLaMA’s
Caveats
- The original pretrained checkpoint remains non-commercial; commercial projects must use the separate
VGGT-1B-Commercialcheckpoint and complete an approval form. - Third-party visualization tools can take tens of seconds with large image sets, which is independent of the model’s own inference speed.
- Single-view reconstruction shows promise but was not quantitatively benchmarked by the authors for monocular depth accuracy.
Verdict
Worth a look if you need fast, feed-forward 3D priors for reconstruction, camera calibration, or splatting pre-processing. Skip it if you require a fully open, no-strings-attached commercial license out of the box.
Frequently asked
- What is facebookresearch/vggt?
- VGGT replaces the traditional multi-stage 3D reconstruction pipeline with a single feed-forward model that predicts cameras, depth, and geometry from one or many images in seconds.
- Is vggt open source?
- Yes — facebookresearch/vggt is an open-source project tracked on heatdrop.
- What language is vggt written in?
- facebookresearch/vggt is primarily written in Python.
- How popular is vggt?
- facebookresearch/vggt has 14k stars on GitHub and is currently holding steady.
- Where can I find vggt?
- facebookresearch/vggt is on GitHub at https://github.com/facebookresearch/vggt.