01
shiyu-coder/Kronos
+275 ★/day↗accelerating
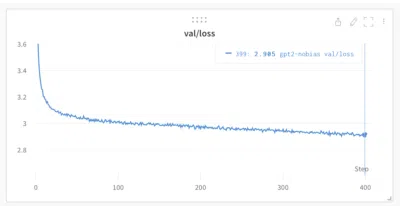
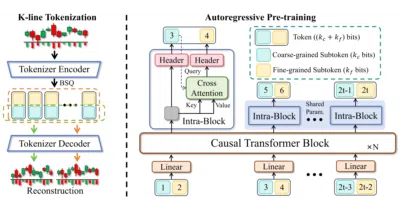
Kronos recasts noisy, multi-dimensional candlestick data as hierarchical discrete tokens so an autoregressive Transformer can forecast financial markets like a language model.
Kronos recasts noisy, multi-dimensional candlestick data as hierarchical discrete tokens so an autoregressive Transformer can forecast financial markets like a language model.
MiniMind is an educational training ground that rebuilds every stage of a modern language model—from tokenizer to RLHF—in raw PyTorch so you can see the gears turning instead of just calling high-level APIs.
Official Jupyter notebooks demonstrating how to wire Claude into production tasks like RAG, SQL queries, and multimodal pipelines.
GraphRAG exists to give LLMs a structured memory layer for reasoning over messy, private narrative text.
A hosted proxy that offers free, rate-limited API access to GPT, DeepSeek, and others for Chinese users who'd rather not tunnel through a VPN.
It teaches how LLMs work by implementing tokenization, attention, pretraining, and finetuning in pure PyTorch, one notebook at a time.
STORM simulates expert research conversations so LLMs can write long, cited articles from scratch.
It centralizes model definitions so the same architecture works across PyTorch, JAX, vLLM, and llama.cpp without rewrites.
Official Python notebooks and guides for common OpenAI API tasks.
Mozilla wraps llama.cpp and a full model into a single cross-platform executable using an obscure libc trick.
Because swapping from GPT-4o to Claude shouldn't require rewriting your request plumbing.
Microsoft built an inference engine that lets a single CPU run a 100B-parameter model at human reading speed by using 1.58-bit weights.
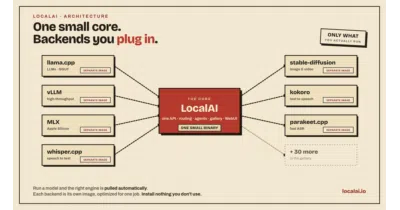
LocalAI wraps 36+ inference engines behind one OpenAI-compatible API and pulls them on demand, so you can run LLMs, vision, voice, and video on anything from a CPU to a Jetson.
A curated directory of software, plugins, and frameworks that integrate with the DeepSeek API, maintained by DeepSeek itself.
A maintainer cataloged every Chinese NLP repo they touched into a single, obsessively categorized list so others wouldn’t have to hunt.
A systematic Chinese tutorial for developers who want to stop treating LLMs as black boxes and hand-build a 215-million-parameter model from the ground up.
A Python framework for building production multi-agent systems that leans on LLM reasoning instead of rigid prompt choreography.
A rewrite of minGPT that prioritizes working, hackable training code over educational scaffolding.
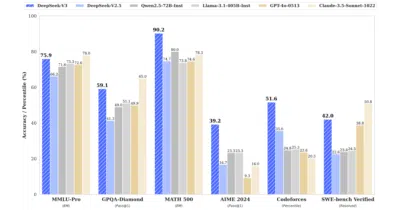
DeepSeek-V3 exists to prove that a 671-billion-parameter model can train end-to-end without a single rollback, activate only 37B parameters per token, and still match leading closed-source systems.
Because training a transformer shouldn't require 245MB of PyTorch just to multiply matrices.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.