microsoft/BitNet
Squeezing 100B-parameter LLMs onto a single CPU, 1.58 bits at a time
Microsoft built an inference engine that lets a single CPU run a 100B-parameter model at human reading speed by using 1.58-bit weights.
Velocity · 7d
+6.3
★ / day
Trend
↘cooling
star history
What it does
bitnet.cpp is an inference framework for 1-bit (specifically 1.58-bit) LLMs. It takes models with ternary weights and runs them on standard CPUs and GPUs using a suite of optimized kernels. The project claims a 100B-parameter BitNet model can run on a single CPU at roughly 5–7 tokens per second, which is comparable to human reading speed. It is based on the llama.cpp framework and layers its own lookup-table kernels on top.
The interesting bit
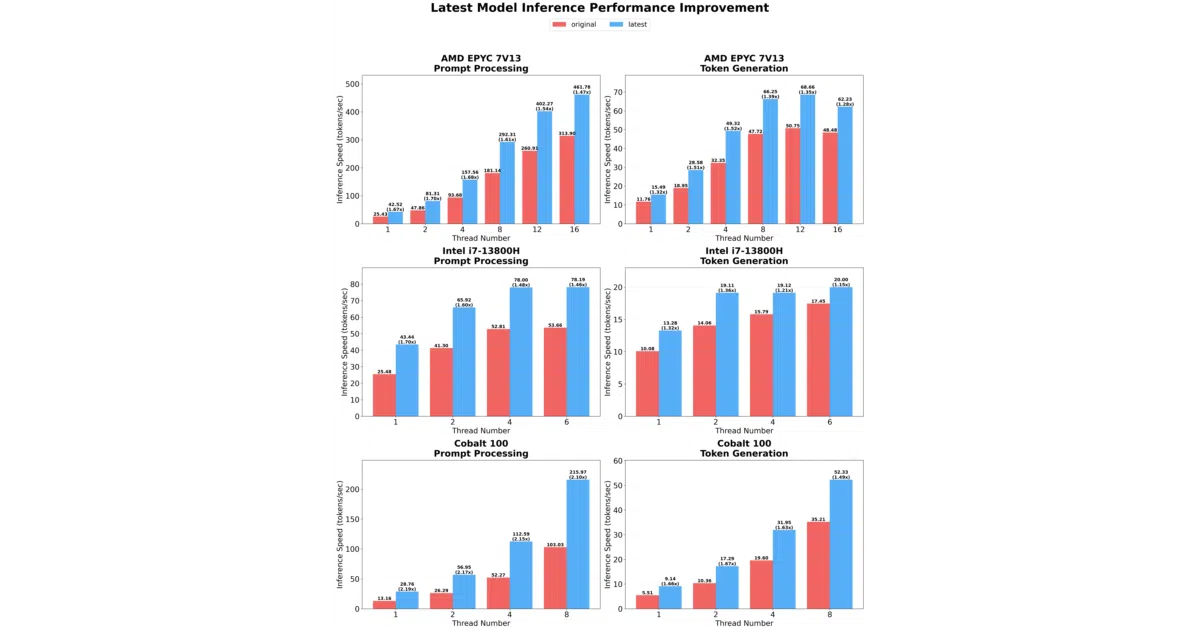
The real work happens in the kernel tiling and lookup-table tricks borrowed from Microsoft’s earlier T-MAC research. By quantizing not just weights but also embeddings, and by using architecture-specific kernels (I2_S, TL1, TL2), the framework squeezes out additional speedups—up to 2.1× on top of the already aggressive baseline—while keeping inference lossless.
Key highlights
- Runs a 100B BitNet b1.58 model on a single CPU at 5–7 tokens per second.
- Claims 1.37×–5.07× speedup on ARM and 2.37×–6.17× on x86, with energy reductions of 55.4%–82.2%.
- Latest optimizations add configurable tiling and embedding quantization for another 1.15×–2.1× gain.
- Supports a handful of Hugging Face models (BitNet, Llama3-8B-1.58, Falcon3, Falcon-E) with varying kernel coverage.
- GPU inference is now supported; NPU support is listed as coming next.
Caveats
- Kernel support is fragmented: not every model runs every kernel on every architecture, so check the compatibility matrix before assuming your hardware is covered.
- The README is upfront that this is meant to inspire more 1-bit LLM development, implying the ecosystem is still small.
- NPU support is promised but not yet available.
Verdict
Hardware-constrained developers and edge-inference tinkerers should look here, especially if you are curious about sub-2-bit quantization. If you need a general-purpose engine for standard 4-bit or 8-bit models, stick with upstream llama.cpp or T-MAC.
Frequently asked
- What is microsoft/BitNet?
- Microsoft built an inference engine that lets a single CPU run a 100B-parameter model at human reading speed by using 1.58-bit weights.
- Is BitNet open source?
- Yes — microsoft/BitNet is open source, released under the MIT license.
- What language is BitNet written in?
- microsoft/BitNet is primarily written in C++.
- How popular is BitNet?
- microsoft/BitNet has 39.8k stars on GitHub and is currently cooling off.
- Where can I find BitNet?
- microsoft/BitNet is on GitHub at https://github.com/microsoft/BitNet.