01
microsoft/markitdown
+526 ★/day↗accelerating
A Python utility that converts office documents and media into structured Markdown built for LLM pipelines, not human eyeballs.
A Python utility that converts office documents and media into structured Markdown built for LLM pipelines, not human eyeballs.
Built in a fit of rage after a $16 “open source” web-to-Markdown tool gated features behind API tokens.
It translates scientific papers into bilingual PDFs while keeping formulas, charts, and annotations exactly where they belong.
Firecrawl turns search, scraping, and browser interaction into a single API so your agents can read the web without wrestling with proxies, rate limits, or JavaScript rendering.
Repomix exists because copy-pasting twenty files into a chat window is a terrible way to ask an LLM for help.
A maintainer cataloged every Chinese NLP repo they touched into a single, obsessively categorized list so others wouldn’t have to hunt.
It collects the best social-media experiments with a Gemini-2.5-flash-image derivative and releases a 150k identity-consistent dataset for the community.
Chroma is an open-source search backend that handles the messy embedding pipeline so AI applications can store and retrieve documents with a minimal API.
Because someone has to label the training data, and it might as well not be in a spreadsheet.
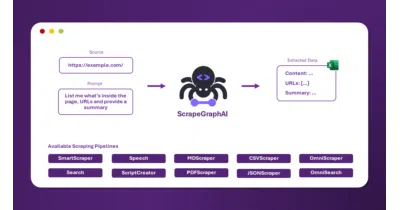
ScrapeGraphAI lets you extract structured data from websites and documents by describing what you want in plain English, leaving the LLM to wrestle with the markup.
It turns images and PDFs into structured JSON and Markdown so your RAG pipeline doesn't have to squint.
It re-encodes JSON into a token-cheaper, schema-explicit format so you can fit more context into LLM prompts without losing structure.
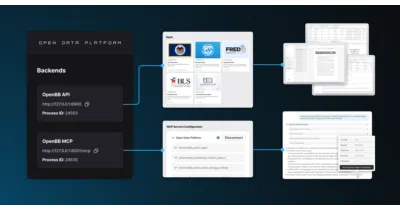
OpenBB normalizes proprietary and public financial data so engineers can feed the same sources to Python scripts, REST APIs, Excel, and AI agents without rebuilding integrations.
It exists to handle the tedious wiring—annotations, dataset formats, tracking—that sits between a trained model and a useful application.
A curated awesome-list that tries to answer "What is Data Science, and what should I study?" by cataloging courses, tools, libraries, and communities in a single sprawling index.
OpenDataLoader PDF exists to extract structured data from PDFs for AI pipelines while auto-tagging untagged documents for screen readers, all without proprietary dependencies.
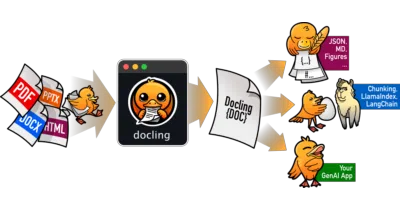
Docling turns PDFs, Office files, images, and even audio into structured AI-ready formats, entirely on your own hardware.
MinerU turns PDFs, Office files, and images into structured Markdown and JSON so LLM agents don’t drown in layout noise.
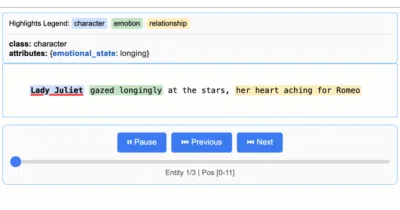
LangExtract exists because asking an LLM to pull names and dates out of a report is easy; proving exactly which sentence each came from is the hard part.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.