ScrapeGraphAI/Scrapegraph-ai
Web scraping without the CSS selector archaeology
ScrapeGraphAI lets you extract structured data from websites and documents by describing what you want in plain English, leaving the LLM to wrestle with the markup.
Velocity · 7d
+25
★ / day
Trend
↘cooling
star history
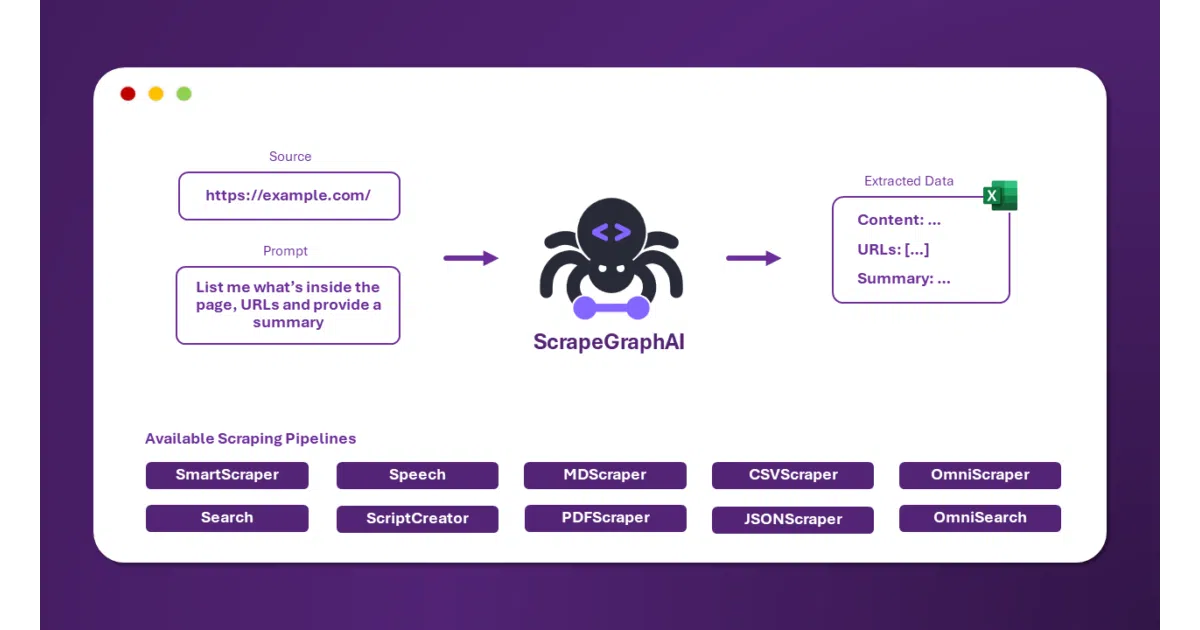
What it does ScrapeGraphAI is a Python library that fetches web pages—or local files like HTML, XML, JSON, and Markdown—and extracts structured data from a natural-language prompt. You ask for founder names, social links, or product descriptions, and it returns a dictionary. It relies on Playwright for rendering and can call cloud LLMs or run locally through Ollama.
The interesting bit
The library frames scraping as a pipeline of “graphs”: SmartScraperGraph handles single pages, SearchGraph crawls across top search results, and oddball variants like SpeechGraph or ScriptCreatorGraph spit out audio files or Python scripts instead of raw JSON. The README never quite explains what “direct graph logic” means under the hood, but the pipeline abstraction keeps prompt-to-output workflows modular.
Key highlights
- Prompt-driven extraction: describe the data and get back a structured dictionary.
- Pluggable LLM backends: OpenAI, Azure, Gemini, Groq, MiniMax, or local Ollama models.
- Parallel “multi” pipelines for batching requests across several URLs at once.
- Hooks into LangChain, LlamaIndex, Crew.ai, and low-code platforms like Zapier, n8n, and Bubble.
- Telemetry is on by default; opting out requires setting an environment variable.
Caveats
- The documentation is heavily tilted toward upselling the hosted commercial API.
- Core concepts like the “direct graph logic” are asserted but not detailed, so the architectural benefits are unclear.
- Telemetry is opt-out, not opt-in.
Verdict Worth a look if you build prototypes or one-off data pipelines and would rather write English than maintain brittle selectors. Avoid it if you need deterministic, low-latency extraction or cannot ship page content to external LLMs.
Frequently asked
- What is ScrapeGraphAI/Scrapegraph-ai?
- ScrapeGraphAI lets you extract structured data from websites and documents by describing what you want in plain English, leaving the LLM to wrestle with the markup.
- Is Scrapegraph-ai open source?
- Yes — ScrapeGraphAI/Scrapegraph-ai is open source, released under the MIT license.
- What language is Scrapegraph-ai written in?
- ScrapeGraphAI/Scrapegraph-ai is primarily written in Python.
- How popular is Scrapegraph-ai?
- ScrapeGraphAI/Scrapegraph-ai has 28.6k stars on GitHub and is currently cooling off.
- Where can I find Scrapegraph-ai?
- ScrapeGraphAI/Scrapegraph-ai is on GitHub at https://github.com/ScrapeGraphAI/Scrapegraph-ai.