docling-project/docling
Parsing PDFs like a human, not a photocopier
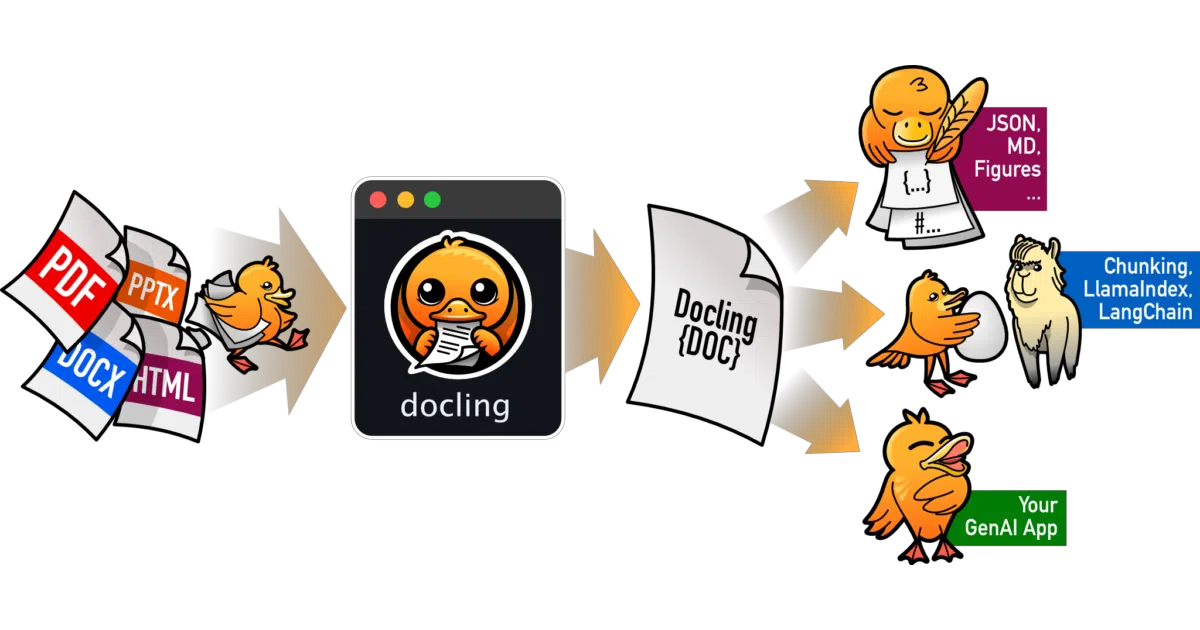
Docling turns PDFs, Office files, images, and even audio into structured AI-ready formats, entirely on your own hardware.
Velocity · 7d
+68
★ / day
Trend
↘cooling
star history
What it does
Docling ingests a sprawling list of document formats—PDF, DOCX, PPTX, XLSX, HTML, images, LaTeX, audio, and WebVTT—and normalizes them into a unified structured representation called DoclingDocument. It then exports to Markdown, JSON, HTML, or specialized formats like DocTags. The entire pipeline is designed to run locally, which matters when your documents are too sensitive for a cloud API.
The interesting bit
Most parsers treat a PDF as a bag of text; Docling attempts to reconstruct the original intent—reading order, table geometry, formulas, code blocks, and even chart types like bar or pie plots. It also doubles as an MCP server, letting agentic frameworks invoke it as a native tool. The project started at IBM Research Zurich and graduated to the LF AI & Data Foundation, so it has the institutional backing of a research lab rather than a weekend hack.
Key highlights
- Advanced PDF understanding including layout, reading order, tables, formulas, and image classification.
- OCR for scanned documents and support for Visual Language Models such as
GraniteDocling. - Fully local execution for air-gapped environments, plus integrations for LangChain, LlamaIndex, Crew AI, and Haystack.
- Handles domain-specific XML schemas like USPTO patents, JATS articles, and XBRL financial reports.
- MCP server support for agentic applications and a built-in CLI.
Caveats
- Structured information extraction is marked as beta.
- Metadata extraction and complex chemistry understanding are listed as “coming soon,” not shipped.
- Python 3.9 support was dropped as of version 2.70.0.
Verdict
Reach for Docling if your AI pipeline needs to digest real-world documents that are full of tables, charts, and scanned pages. If your input is already clean structured text, you probably do not need this much machinery.
Frequently asked
- What is docling-project/docling?
- Docling turns PDFs, Office files, images, and even audio into structured AI-ready formats, entirely on your own hardware.
- Is docling open source?
- Yes — docling-project/docling is open source, released under the MIT license.
- What language is docling written in?
- docling-project/docling is primarily written in Python.
- How popular is docling?
- docling-project/docling has 63.6k stars on GitHub and is currently cooling off.
- Where can I find docling?
- docling-project/docling is on GitHub at https://github.com/docling-project/docling.