openinfer-project/openinfer
Serving trillion-parameter LLMs from scratch in Rust and CUDA
Built to prove that hand-written Rust kernels and no framework runtime can serve frontier models without the bloat.
Collecting fresh signals — velocity needs a few days of history.
collecting data…
star history
What it does
openinfer is an LLM inference engine written entirely in Rust and hand-written CUDA. It drops PyTorch, ONNX, and any framework runtime, auto-detecting supported models from config.json and exposing an OpenAI-compatible /v1/completions endpoint. The default build serves Qwen3 purely from Rust and CUDA with zero Python at runtime; other model lines like Qwen3.5, DeepSeek V4, and Kimi-K2 are gated behind compile-time features that pull in build-only tools such as Triton or TileLang.
The interesting bit
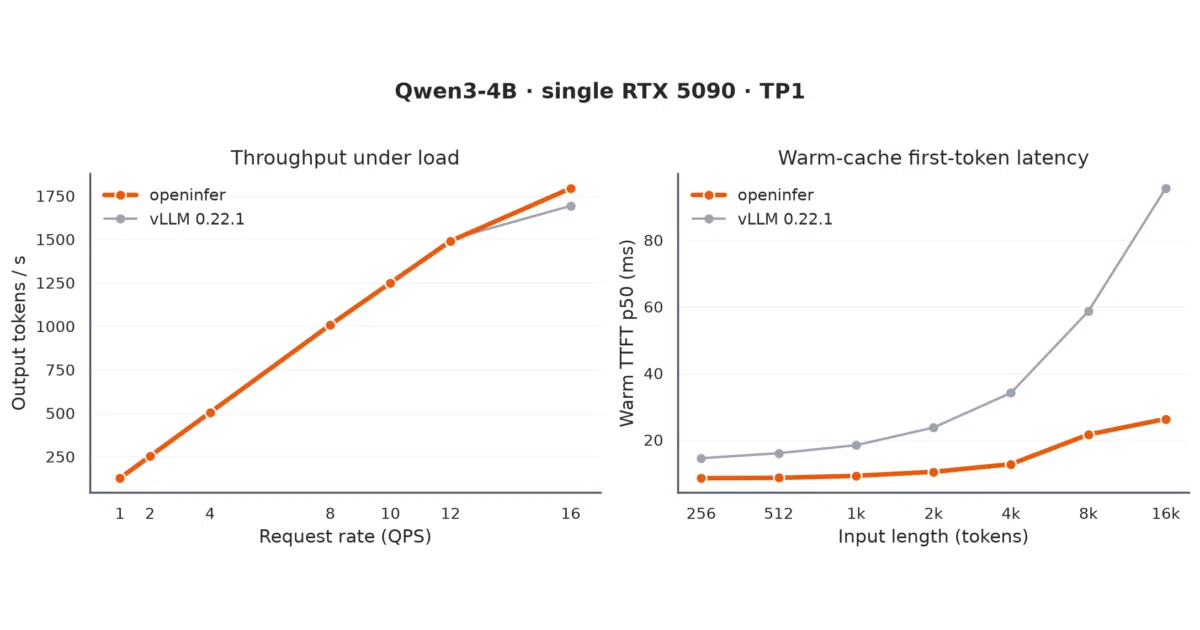
Instead of wrapping an existing stack, the project re-implements kernels, schedulers, and KV management from scratch. Benchmarks on an RTX 5090 show a roughly 5× smaller memory footprint and a 3-second cold start versus vLLM’s 70 seconds, while saturated throughput edges slightly ahead on Qwen3-4B. It also implements host-tier KV offload, turning a 1.14 s cold prefill into a 126 ms restore for cached prefixes at 16k context.
Key highlights
- Serves models from 4B Qwen3 up to trillion-parameter Kimi-K2 and 671B DeepSeek-V4-Flash.
- Resident memory idle footprint of 771 MB loaded versus vLLM’s 3.8 GB in reported Qwen3-4B tests.
- Warm prefix-cache latency stays flat as context grows (~26 ms at 16k tokens) with tight p99 variance.
- OpenAI-compatible completions API with streaming, though sampling and logprob support varies by model path.
- Per-model engine crates keep the core runtime shared while isolating model-specific logic.
Caveats
- DeepSeek V4 support is intentionally narrow in the initial release: greedy decoding only, no CUDA Graph yet, and unsupported sampling parameters are rejected with a
stop_reasonrather than executed. - vLLM still leads on some Qwen3.5-4B decode and high-concurrency HTTP benchmarks, so the “holds its own” claim is workload-dependent.
- Most frontier model paths (Qwen3.5, DeepSeek V4, Kimi-K2) require rebuilding the server with specific cargo features and build-time Python tooling; only the Qwen3 path is pure Rust out of the box.
Verdict
Developers who want a lightweight, fast-starting inference runtime for NVIDIA GPUs—especially on Qwen3-class models—should take a look. If you need broad, battle-tested support for every sampling mode and model variant today, vLLM remains the safer default.
Frequently asked
- What is openinfer-project/openinfer?
- Built to prove that hand-written Rust kernels and no framework runtime can serve frontier models without the bloat.
- Is openinfer open source?
- Yes — openinfer-project/openinfer is open source, released under the Apache-2.0 license.
- What language is openinfer written in?
- openinfer-project/openinfer is primarily written in Rust.
- How popular is openinfer?
- openinfer-project/openinfer has 501 stars on GitHub.
- Where can I find openinfer?
- openinfer-project/openinfer is on GitHub at https://github.com/openinfer-project/openinfer.