01
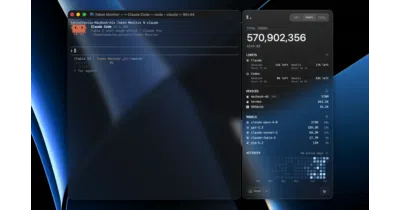
Javis603/token-monitor
+36% /wk +51 ★/day↗accelerating
Token Monitor reads local logs from two dozen AI coding tools to surface live token burn, costs, and limits in one place, synced across all your machines.
Token Monitor reads local logs from two dozen AI coding tools to surface live token burn, costs, and limits in one place, synced across all your machines.
Because your coding assistant shouldn't need a securities API cheat sheet to analyze A-shares.
Turns URLs into clean markdown and JSON so AI agents don't have to parse HTML soup.
It turns technical PDFs and EPUBs into on-demand Claude Code skills, so you can query a book's actual frameworks instead of hoping the model remembers them.
It removes the visible Gemini sparkle, invisible SynthID fingerprints, and C2PA metadata that AI image generators embed in every output.
It exists to automate the tedious pipeline of turning noisy PDFs and plain text into structured training data for domain-specific LLMs.
Uses multimodal LLMs to transcribe PDFs into Markdown, preserving complex layouts that traditional extractors mangle.
This unofficial rebuild of a Google Research project chains specialized agents to turn rough text and data into publication-ready academic figures.
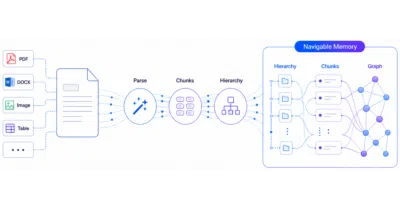
A pipeline that turns messy PDFs and slides into structured, navigable memory for AI agents instead of flat text shards.
Unstract turns document extraction into a prompt-and-deploy workflow instead of a regex archaeology dig.
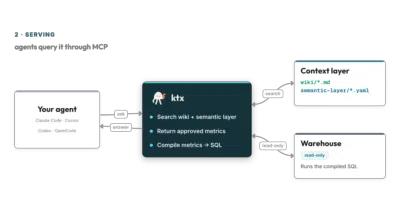
ktx is a local context layer that ingests your data stack and business knowledge so Claude, Codex, and other agents query warehouses with approved metrics instead of inventing SQL.
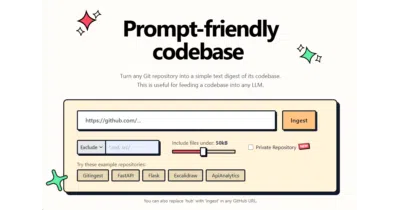
It turns Git repositories into flat, token-counted text digests so you can stop manually concatenating files for LLM prompts.
Maxun is an open-source platform for developers who would rather record a browsing session than write another brittle web scraper.
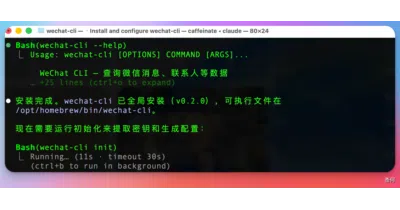
Scans running WeChat process memory to extract SQLCipher keys, then exposes your chat database as a JSON-first CLI designed for AI agent consumption.
It captures the messy reality of long-horizon agent tasks and turns execution traces into reusable, shareable learning signals.
It scrapes WeChat public articles and serves them as RSS, Markdown, and JSON because Tencent won’t.
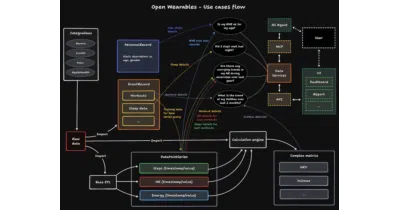
Open Wearables wants to unify fitness tracker data behind one self-hosted API so developers can stop writing bespoke OAuth flows for every wearable brand.
olmOCR exists because LLMs cannot train on PDFs until someone strips the formatting chaos and restores natural reading order.
A cross-platform Electron app that runs speech recognition locally, then hands the results off to anything from Baidu to DeepSeek for translation.
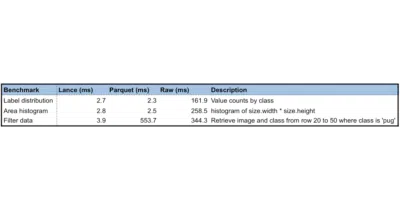
Lance treats vectors, images, and embeddings as first-class citizens instead of awkward guests at Parquet's SQL-only party.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.