Ontos-AI/knowhere
Document parsing that remembers where it put things
A pipeline that turns messy PDFs and slides into structured, navigable memory for AI agents instead of flat text shards.
Velocity · 7d
+4.3
★ / day
Trend
↘cooling
star history
What it does
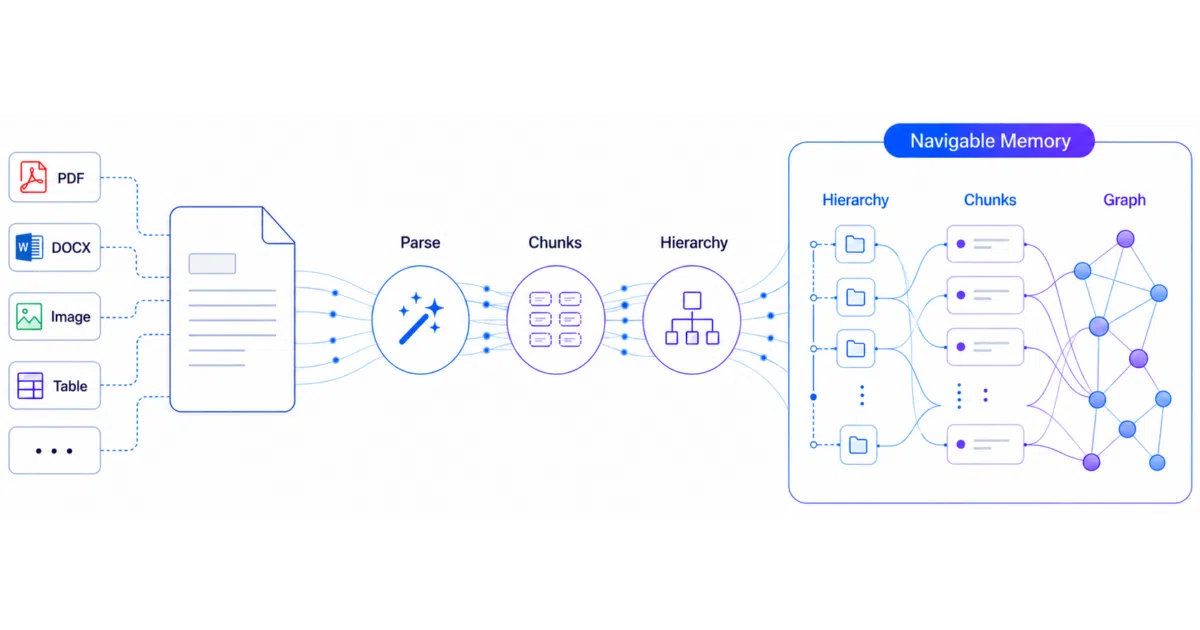
Knowhere ingests unstructured documents—PDFs, Office files, images, tables, Markdown—and outputs structured chunks with full hierarchy intact. It stores them as a navigable memory graph that agents can query, traverse, and cite. The project is the backend API and worker; a separate dashboard repo provides the web UI.
The interesting bit
Most chunking flattens documents into semantic confetti. Knowhere uses a tree-like algorithm to reconstruct document hierarchy, then links chunks across documents into a lightweight graph. Agents don’t just retrieve nearest-neighbor vectors; they walk section trees and cross-document relationships the way a human skims a table of contents.
Key highlights
- Multi-modal parsing with VLM summaries for images and tables, linked back to source chunks
- Hybrid retrieval fusing keyword, path, content, and semantic signals, plus agentic navigation
- Model-agnostic LLM/VLM support: defaults to DeepSeek and Qwen-VL, swappable via env vars
- Uses MinerU as default parser but explicitly decouples from it—any Markdown-outputting tool works
- Apache 2.0, with Docker Compose self-hosting option and managed cloud API at knowhereto.ai
Caveats
- Requires a small constellation of external services: PostgreSQL, Redis, S3-compatible storage, and at least one LLM API key to do much of anything
- Benchmarks shown are internal evaluations with limited public detail; the README notes they’re “actively expanding”
- Several formats (EPUB, HTML, audio, video, and a curious
.skills.md) are listed as “coming soon”
Verdict
Worth a look if you’re building agentic RAG and tired of watching your LLM lose the plot across flattened document chunks. Skip it if you need a quick, zero-dependency document parser—this is memory infrastructure, not a drop-in replacement for MinerU or Markitdown.
Frequently asked
- What is Ontos-AI/knowhere?
- A pipeline that turns messy PDFs and slides into structured, navigable memory for AI agents instead of flat text shards.
- Is knowhere open source?
- Yes — Ontos-AI/knowhere is open source, released under the Apache-2.0 license.
- What language is knowhere written in?
- Ontos-AI/knowhere is primarily written in Python.
- How popular is knowhere?
- Ontos-AI/knowhere has 1.9k stars on GitHub and is currently cooling off.
- Where can I find knowhere?
- Ontos-AI/knowhere is on GitHub at https://github.com/Ontos-AI/knowhere.