OpenDCAI/DataFlow
LLM data prep that thinks in operators, not scripts
It exists to automate the tedious pipeline of turning noisy PDFs and plain text into structured training data for domain-specific LLMs.
Velocity · 7d
+57
★ / day
Trend
↗accelerating
star history
What it does
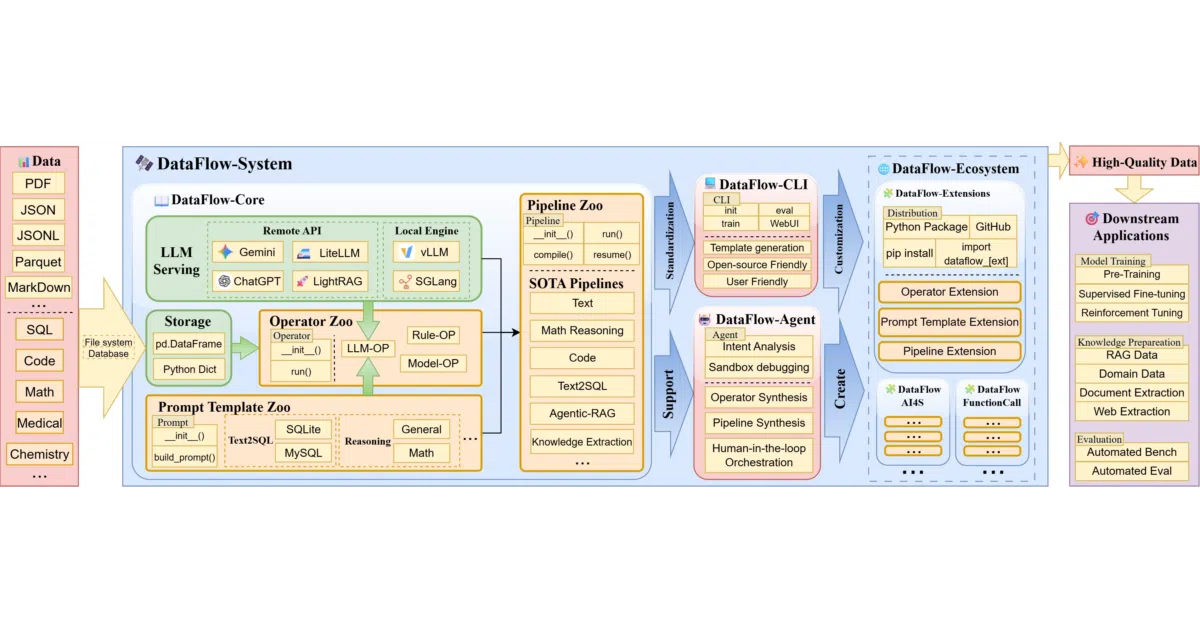
DataFlow ingests messy inputs like PDFs and low-quality QA pairs, then runs them through a sequence of operators that generate, refine, evaluate, and filter content into structured datasets. The output feeds domain-specific LLM training—pre-training, supervised fine-tuning, reinforcement learning, or RAG—in fields like healthcare, finance, and legal research. Workflows are packaged as reproducible pipelines built from reusable Python blocks.
The interesting bit
The project adopts a PyTorch-like hierarchy of Pipeline → Operator → Prompt, which makes complex data governance feel like stacking model layers. It also includes a DataFlow-agent that attempts to dynamically assemble or even create new operators on demand, though the README leaves the depth of that automation unclear.
Key highlights
- 100+ pipeline-specific operators and 10+ core interaction patterns covering generation, evaluation, filtering, and refinement
- Visual WebUI for drag-and-drop pipeline construction
- Ecosystem includes distributed orchestration via RayOrch, a dedicated Agent module, and domain-specific extensions like DataFlow-MM
- Custom operators are first-class: package and distribute them via GitHub or PyPI
- Academic backing: Text2SQL and math data workflows accepted at ICDE 2026 and KDD 2026
Caveats
- The README is heavy on marketing emojis and light on concrete benchmarks against the Nemo-Curator and Data-Juicer systems it name-checks
- The
DataFlow-agentis described as creating operators dynamically, but the sources do not clarify whether this is full automation or assisted composition
Verdict
Teams building domain-specific LLMs who need to convert messy PDFs or unstructured text into QA pairs should look here; if you already have clean, structured data and just need simple filtering, it is likely overkill.
Frequently asked
- What is OpenDCAI/DataFlow?
- It exists to automate the tedious pipeline of turning noisy PDFs and plain text into structured training data for domain-specific LLMs.
- Is DataFlow open source?
- Yes — OpenDCAI/DataFlow is open source, released under the Apache-2.0 license.
- What language is DataFlow written in?
- OpenDCAI/DataFlow is primarily written in Python.
- How popular is DataFlow?
- OpenDCAI/DataFlow has 6.7k stars on GitHub and is currently accelerating.
- Where can I find DataFlow?
- OpenDCAI/DataFlow is on GitHub at https://github.com/OpenDCAI/DataFlow.