Kaelio/ktx
Teaching AI agents not to hallucinate your revenue numbers
ktx is a local context layer that ingests your data stack and business knowledge so Claude, Codex, and other agents query warehouses with approved metrics instead of inventing SQL.
Velocity · 7d
+5.1
★ / day
Trend
↗accelerating
star history
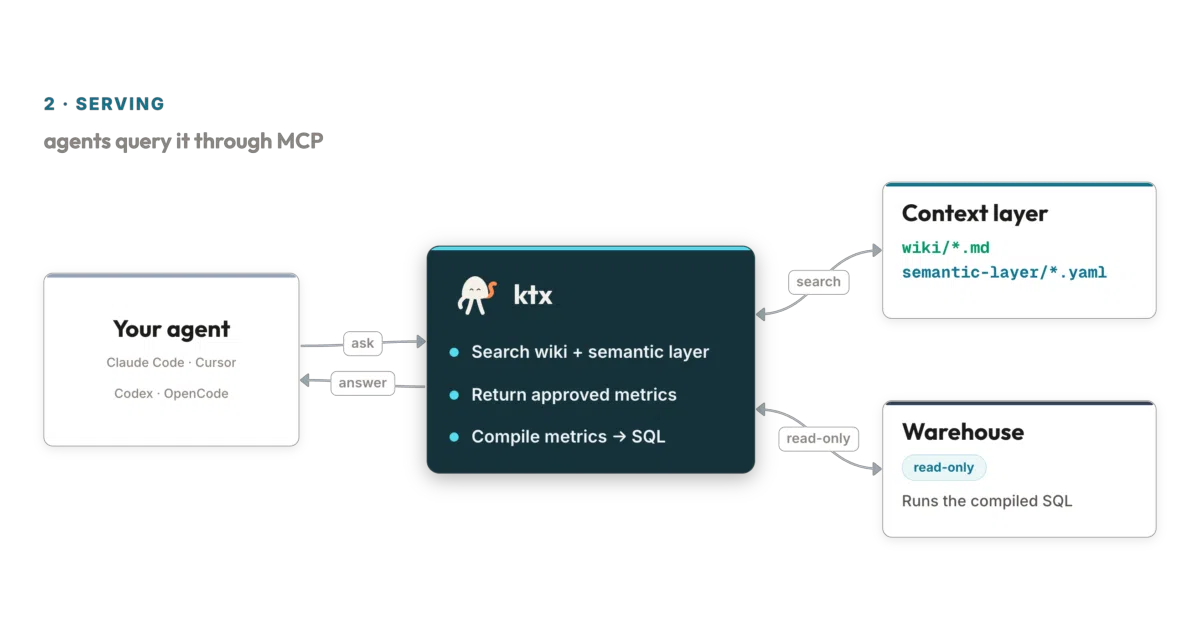
What it does
ktx runs locally as a CLI tool and MCP server. It scans your warehouse (Postgres, Snowflake, BigQuery, etc.), ingests dbt/Looker/Metabase/Notion sources, builds a searchable wiki and YAML semantic layer, then exposes that context to agents. When an agent asks “what’s Q3 revenue?”, ktx returns approved metric definitions and compiles read-only SQL rather than letting the model guess joins and filters.
The interesting bit
The project treats “context” as executable, not just documentation. It auto-detects joinable columns, resolves fan and chasm traps in the join graph, and flags contradictions across your wiki and semantic sources for human review. That’s the unglamorous plumbing that usually breaks agent-generated queries.
Key highlights
- Runs entirely local; no hosted service, no extra billing beyond your own LLM keys
- Read-only by design; agents cannot write to the warehouse through ktx
- Ingests and reconciles across dbt, MetricFlow, LookML, Metabase, Notion, and raw tables
- Ships CLI + MCP server for Claude Code, Codex, Cursor, OpenCode
- Python query planner (
python/ktx-sl) plus TypeScript CLI/context engine in one pnpm+uv workspace
Caveats
- Requires an existing SQL warehouse; useless without one
- Setup involves configuring providers, connections, and running ingestion before agents can query accurately
- Telemetry is on by default for CLI runs (anonymous, but still opt-out rather than opt-in)
Verdict
Worth a look if your analytics team is tired of agents returning “revenue” numbers that don’t match dbt. Skip it if you just need occasional ad-hoc queries or lack a warehouse to point it at.
Frequently asked
- What is Kaelio/ktx?
- ktx is a local context layer that ingests your data stack and business knowledge so Claude, Codex, and other agents query warehouses with approved metrics instead of inventing SQL.
- Is ktx open source?
- Yes — Kaelio/ktx is open source, released under the Apache-2.0 license.
- What language is ktx written in?
- Kaelio/ktx is primarily written in TypeScript.
- How popular is ktx?
- Kaelio/ktx has 1.5k stars on GitHub and is currently accelerating.
- Where can I find ktx?
- Kaelio/ktx is on GitHub at https://github.com/Kaelio/ktx.