01
karpathy/nanochat
+230 ★/day→steady
Karpathy's minimal LLM training harness turns a $43K 2019 training run into a sub-$100 afternoon project.
Karpathy's minimal LLM training harness turns a $43K 2019 training run into a sub-$100 afternoon project.
A step-by-step PyTorch walkthrough that trains a small-but-real LLM on ordinary laptops, no external libraries allowed.
A weekend research hack that reverse-engineers private APIs to run backpropagation on the Neural Engine Apple reserves for inference only.
Unsloth Studio wraps training, inference, and RL into a single web UI with aggressive memory optimizations.
exo automatically clusters your Apple devices to run frontier models that won't fit on one machine, using Thunderbolt like a datacenter backplane.
One framework claims to handle 100+ LLMs and VLMs with zero-code CLI and a web UI—backed by enough quantization methods to make a compression engineer weep.
MiniMind-O is a from-scratch Omni implementation small enough to train in ~2 hours on a single RTX 3090, designed for developers who want to understand the full pipeline rather than download a black box.
A stripped-down workshop that trades GPT-2 scale for the clarity of writing every transformer component yourself.
A community effort to reverse-engineer and openly reproduce the training pipeline behind DeepSeek's famous reasoning model.
Hugging Face's Transformers library became the de facto standard for model definitions by being the boring part everyone agrees on.
Lightricks open-sources the full inference stack and LoRA trainer for their DiT-based audio-video model, complete with camera-control LoRAs and HDR output pipelines.
LeWorldModel cuts JEPA training from six loss hyperparameters to one, then plans 48× faster than foundation-model competitors.
A structured prompt library that teaches Claude Code, Codex, or Gemini how to run the full ML research lifecycle — from literature review to LaTeX.
A deliberately minimal GPT-2 implementation that taught a generation how transformers work, now officially succeeded by nanochat.
Google's ML framework wants to be the entire pipeline, not just the model.
Ultralytics turned the classic object detector into a unified computer-vision Swiss Army knife you can train via CLI or Python.
A from-scratch inference engine that trades the kitchen sink for a readable codebase without tanking throughput.
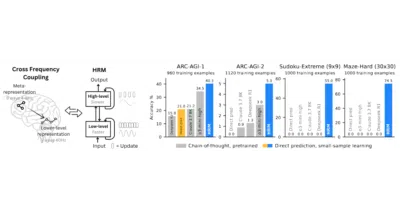
HRM replaces Chain-of-Thought with a brain-inspired recurrent architecture that plans slowly and computes fast, all in one forward pass.
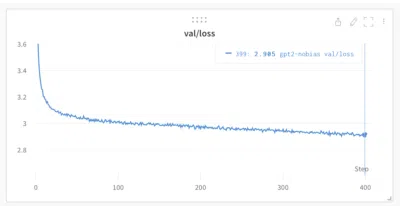
A from-scratch LLM trainer that ditches 245MB of PyTorch dependencies for raw C/CUDA, and somehow runs slightly faster.
DINOv3 is a family of self-supervised vision backbones designed to produce high-quality dense features for everything from semantic segmentation to satellite canopy mapping, often beating task-specialized models out of the box.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.