sapientinc/HRM
A 27M-parameter model that learns Sudoku from 1,000 examples
HRM replaces Chain-of-Thought with a brain-inspired recurrent architecture that plans slowly and computes fast, all in one forward pass.
Not currently ranked — collecting fresh signals.
star history
What it does
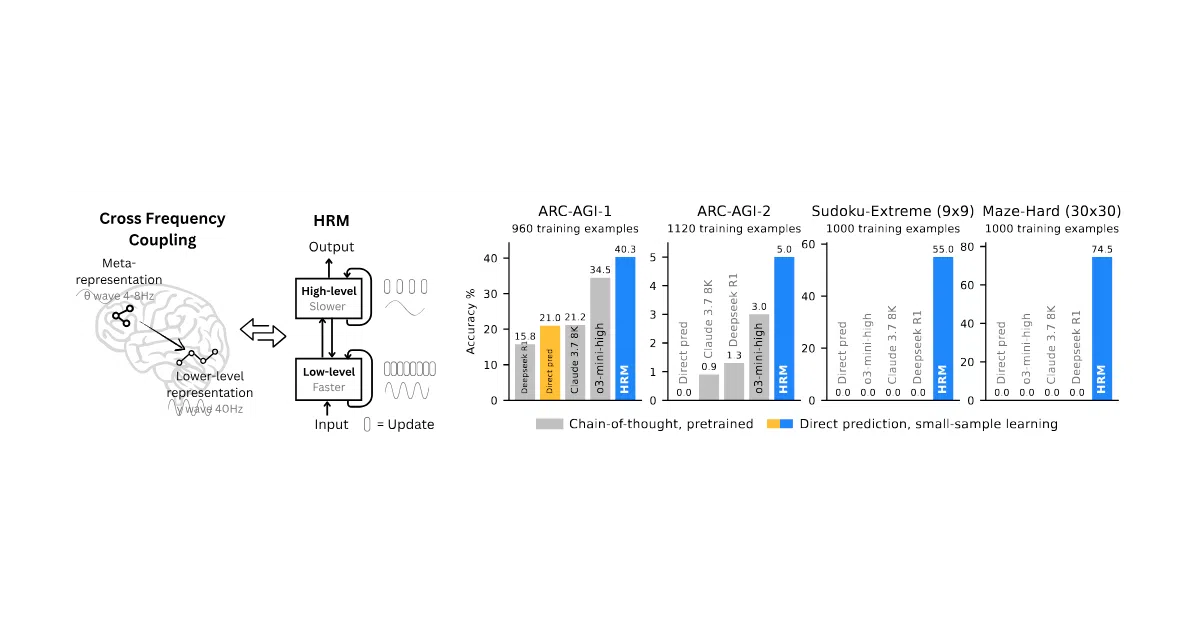
HRM is a recurrent neural network designed for complex reasoning tasks—Sudoku, maze pathfinding, and the ARC-AGI benchmark—without Chain-of-Thought prompting or pre-training. It uses two coupled recurrent modules: a high-level module for slow, abstract planning and a low-level module for rapid, detailed computation. The entire reasoning sequence happens in a single forward pass.
The interesting bit
The architecture borrows from neuroscience’s idea of multi-timescale processing: different brain regions operate at different speeds. HRM applies this to AI by forcing a separation between “what to do” (slow, few steps) and “how to do it” (fast, many steps). The result is a 27-million-parameter model that reportedly outperforms much larger models with longer context windows on ARC-AGI, trained on as few as 1,000 examples.
Key highlights
- Tiny by modern standards: 27M parameters, no pre-training, no CoT supervision.
- Sample-efficient: Trains on 1,000 examples for Sudoku-extreme, maze-30×30-hard, and ARC tasks.
- Single forward pass: No explicit intermediate-step labels; reasoning is emergent from the recurrent dynamics.
- Checkpoints provided: Pre-trained weights available for ARC-AGI-2, Sudoku 9×9 extreme, and maze 30×30 hard.
- Hardware accessible: Sudoku demo trains in ~10 hours on an RTX 4070 laptop GPU; full experiments assume 8 GPUs.
Caveats
- The README’s performance claims (“nearly perfect,” “outperforms much larger models”) lack specific numbers or comparison tables—readers will need the paper for rigor.
- Small-sample training shows ±2 accuracy variance, and Sudoku-extreme can hit numerical instability from late-stage overfitting; early stopping is advised.
- Setup is involved: requires CUDA 12.6, FlashAttention 2 or 3 (with GPU-generation-specific install paths), and Weights & Biases integration.
Verdict
Worth a look if you’re researching sample-efficient reasoning or recurrent alternatives to transformers. Skip it if you need a polished, plug-and-play library—this is research code with a research setup.
Frequently asked
- What is sapientinc/HRM?
- HRM replaces Chain-of-Thought with a brain-inspired recurrent architecture that plans slowly and computes fast, all in one forward pass.
- Is HRM open source?
- Yes — sapientinc/HRM is open source, released under the Apache-2.0 license.
- What language is HRM written in?
- sapientinc/HRM is primarily written in Python.
- How popular is HRM?
- sapientinc/HRM has 12.6k stars on GitHub.
- Where can I find HRM?
- sapientinc/HRM is on GitHub at https://github.com/sapientinc/HRM.