microsoft/VibeVoice
Voice AI that transcribes an hour of audio in a single pass
VibeVoice is a family of open-source speech models from Microsoft built to ingest, transcribe, and generate very long audio sessions—up to an hour—in a single pass.
Velocity · 7d
+42
★ / day
Trend
↗accelerating
star history
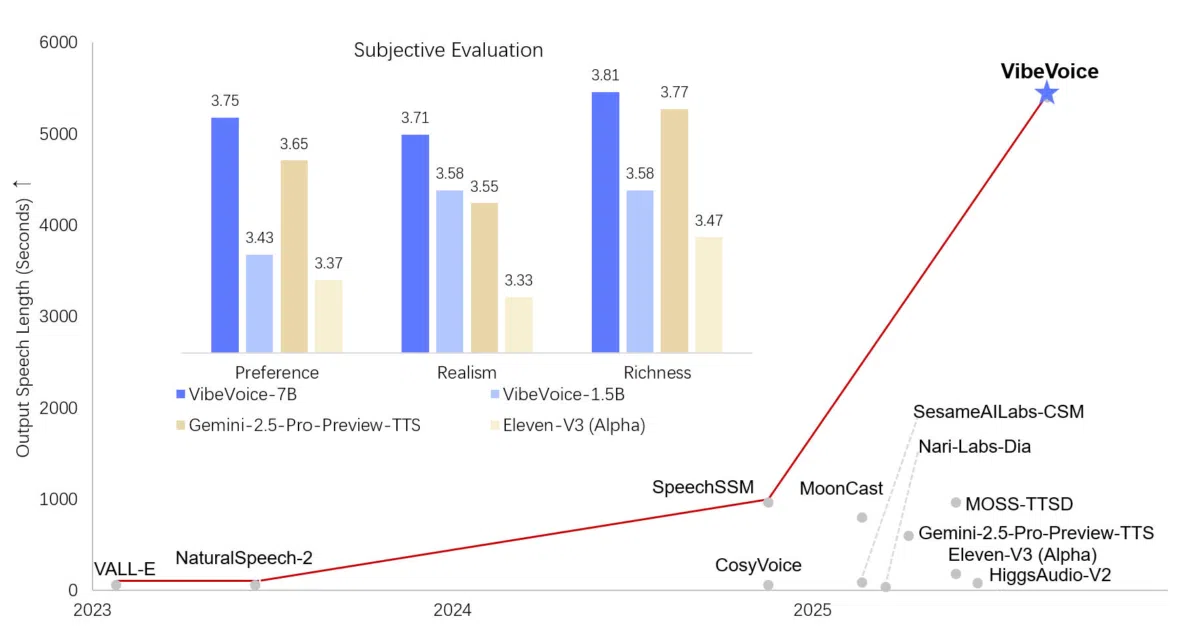
What it does VibeVoice is a collection of speech models that tackles both recognition and synthesis. The ASR model ingests up to 60 minutes of continuous audio in a single pass, outputting structured transcripts that tag speaker identity, timestamps, and content. A lightweight real-time TTS model turns streaming text into speech with a claimed ~300 ms first-audio latency, while a larger long-form TTS model—whose code was removed from the repository after misuse concerns—previously supported 90-minute multi-speaker generation.
The interesting bit Instead of slicing audio into short chunks like conventional ASR, VibeVoice uses continuous speech tokenizers running at just 7.5 Hz—an ultra-low frame rate that preserves fidelity while keeping sequence lengths manageable inside a 64K token context. It pairs a Large Language Model backbone with a diffusion head in a “next-token diffusion” setup: the LLM handles textual context and dialogue flow, while the diffusion layer synthesizes acoustic detail.
Key highlights
- ASR ingests up to 60 minutes of audio in a single 64K-token pass, jointly performing speaker diarization, timestamping, and transcription.
- Users can inject customized hotwords to nudge recognition accuracy for specific names or technical terms.
- The real-time TTS variant is a 0.5B-parameter model built for streaming text input and a claimed ~300 ms first-audio latency.
- ASR is integrated into Hugging Face Transformers and supports vLLM inference; finetuning code is published.
- The long-form TTS training code was removed from the repo in September 2025 after misuse, though model documentation and Hugging Face links remain.
Caveats
- The project explicitly warns against commercial or real-world deployment without further testing, labeling itself research-only and flagging risks of bias inherited from its Qwen2.5 1.5B base.
- High-quality synthetic speech carries obvious deepfake potential; Microsoft notes the TTS code was pulled after misuse and expects lawful, disclosed use.
- The TTS quick-try link is disabled and the 1.5B model code is gone, so anyone hoping to train or run that specific model from source will need to look elsewhere.
Verdict Researchers and developers building meeting transcription, podcast pipelines, or low-latency voice agents should look here—especially for the ASR and real-time TTS pieces. If you need a fully open, reproducible long-form TTS training pipeline, this repository no longer provides it.
Frequently asked
- What is microsoft/VibeVoice?
- VibeVoice is a family of open-source speech models from Microsoft built to ingest, transcribe, and generate very long audio sessions—up to an hour—in a single pass.
- Is VibeVoice open source?
- Yes — microsoft/VibeVoice is open source, released under the MIT license.
- What language is VibeVoice written in?
- microsoft/VibeVoice is primarily written in Python.
- How popular is VibeVoice?
- microsoft/VibeVoice has 50.4k stars on GitHub and is currently accelerating.
- Where can I find VibeVoice?
- microsoft/VibeVoice is on GitHub at https://github.com/microsoft/VibeVoice.