QwenLM/Qwen3-TTS
A TTS model that takes natural-language stage directions
An open-source speech engine that designs voices, clones speakers, and takes emotional direction from plain text.
Velocity · 7d
+19
★ / day
Trend
↗accelerating
star history
What it does
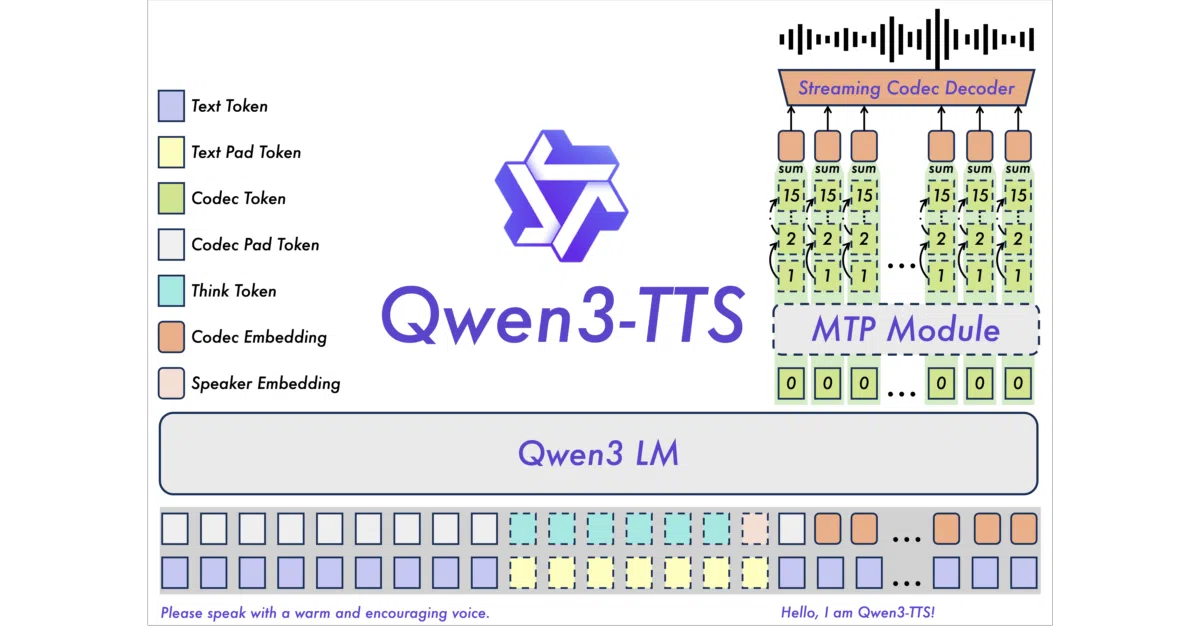
Qwen3-TTS is a family of 0.6B and 1.7B speech generation models from Alibaba’s Qwen team. It covers ten languages and handles three main jobs: reading text in preset voices (CustomVoice), inventing new voices from descriptions (VoiceDesign), and cloning a speaker from a three-second audio clip (Base). All variants support streaming output, and the larger 1.7B models accept natural-language instructions to tweak tone, emotion, and speaking rate.
The interesting bit
Instead of chaining a language model to a separate diffusion transformer—the current fashionable stack—Qwen3-TTS uses a single discrete multi-codebook LM end-to-end, paired with its own Qwen3-TTS-Tokenizer-12Hz to compress speech. The README claims this avoids “cascading errors” and information bottlenecks. The streaming variant is built on a “Dual-Track hybrid” architecture that can spit out the first audio packet after a single input character, with end-to-end latency down to 97 ms.
Key highlights
- 10 languages supported, including Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian
- 1.7B
VoiceDesignandCustomVoicemodels accept natural-language instructions for prosody and timbre control Basemodel supports 3-second rapid voice cloning and can be fine-tuned- Discrete multi-codebook LM architecture without a separate DiT stage
- Streaming and non-streaming generation in one model; claimed end-to-end latency as low as 97 ms
- Available via Hugging Face, ModelScope, and a
qwen-ttsPyPI package
Caveats
- Only the 1.7B variants support natural-language instruction control; the 0.6B models do not.
- The README states that additional models described in the technical report have not yet been released.
- FlashAttention 2 is strongly recommended for GPU memory efficiency, and its build process is noted to be resource-intensive.
Verdict
Worth a look if you need multilingual TTS with voice cloning or promptable emotional control in a single model. Skip it if you are looking for a lightweight, CPU-friendly synthesizer—the code examples target CUDA and the models are transformer-sized.
Frequently asked
- What is QwenLM/Qwen3-TTS?
- An open-source speech engine that designs voices, clones speakers, and takes emotional direction from plain text.
- Is Qwen3-TTS open source?
- Yes — QwenLM/Qwen3-TTS is open source, released under the Apache-2.0 license.
- What language is Qwen3-TTS written in?
- QwenLM/Qwen3-TTS is primarily written in Python.
- How popular is Qwen3-TTS?
- QwenLM/Qwen3-TTS has 12.6k stars on GitHub and is currently accelerating.
- Where can I find Qwen3-TTS?
- QwenLM/Qwen3-TTS is on GitHub at https://github.com/QwenLM/Qwen3-TTS.