01
pytorch/pytorch
+30 ★/day↗accelerating
PyTorch exists to give researchers and engineers GPU-accelerated tensor math and automatic differentiation without forcing them to leave Python’s debugger and stack traces behind.
PyTorch exists to give researchers and engineers GPU-accelerated tensor math and automatic differentiation without forcing them to leave Python’s debugger and stack traces behind.
It wraps local inference and fine-tuning for open models in a web UI, using custom kernels to squeeze more performance out of desktop GPUs than standard tooling.
It teaches how LLMs work by implementing tokenization, attention, pretraining, and finetuning in pure PyTorch, one notebook at a time.
Google's attempt to own the full machine-learning stack, from research lab to Raspberry Pi.
It exists to let developers run customized vision, text, and audio machine learning across mobile, web, and edge hardware without cloud round-trips.
It centralizes model definitions so the same architecture works across PyTorch, JAX, vLLM, and llama.cpp without rewrites.
For when you outgrow micrograd but still want a deep learning compiler small enough to read and hack.
A rewrite of minGPT that prioritizes working, hackable training code over educational scaffolding.
Because training a transformer shouldn't require 245MB of PyTorch just to multiply matrices.
Ultralytics wants to stop you from stitching together separate repos for every computer vision task by bundling detection, segmentation, tracking, and pose estimation into one YOLO-backed package.
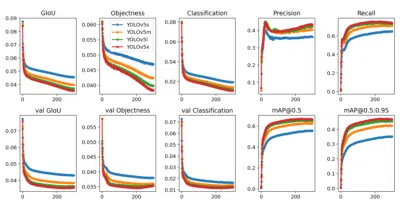
YOLOv5 made real-time object detection as easy as `torch.hub.load`, then exported to everything from iOS to edge chips.
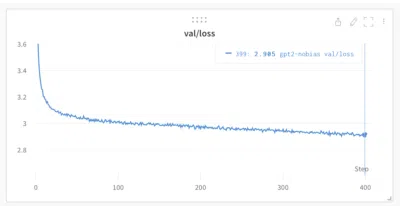
nanochat is a minimal, hackable harness that lets you train and chat with a GPT-2-class LLM on a single GPU node for under $100—no hyperparameter spreadsheets required.
DeepSpeed is the optimization library that let the BLOOM and MT-530B teams train models too large to fit in any single GPU.
A volunteer-maintained Python machine learning module built on SciPy since 2007.
Ray treats distributed computing as a Python primitive, then layers on libraries for training, tuning, serving, and reinforcement learning.
An inference runtime that strips away third-party dependencies to run neural networks on everything from smartphones to smartwatches.
Jupyter notebooks that prove you can write a GPT with little more than high-school calculus and stubbornness.
TimesFM is a pretrained decoder-only transformer that turns historical sequences into point and quantile forecasts without training from scratch.
It exists because keeping up with the training loops, quantization tricks, and inference stacks of 100+ models is a full-time job most developers would rather delegate.
It exists to handle the tedious wiring—annotations, dataset formats, tracking—that sits between a trained model and a useful application.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.