01
slvDev/esp32-ai
+202% /wk +392 ★/day→steady
The project squeezes a 28.9-million-parameter language model onto an ESP32-S3 microcontroller by keeping most of its weights in slow flash memory and reading only what each token needs.
The project squeezes a 28.9-million-parameter language model onto an ESP32-S3 microcontroller by keeping most of its weights in slow flash memory and reading only what each token needs.
It breaks the vendor lock on Codex and Claude Code by translating their API calls to any LLM backend you choose.
A demo repo for running extreme-quantized language models locally without needing a research cluster.
An unofficial proxy that borrows your ChatGPT/Codex OAuth tokens to serve a local OpenAI-compatible API, bypassing API credit billing.
AOS Community Edition is a Rust-based agent operating system that lets agents inspect the runtime, spot missing capabilities, and forge their own least-privilege extensions.
It exists to stop your AI gateway from quietly burning through quotas, cash, and expired OAuth tokens without leaving a paper trail.
It keeps the entire agent loop—prompts, tool calls, browser state, and memory—on your laptop so you don't have to rent a control plane in the cloud.
A Go proxy that tricks Claude Code into using $5/month open models through OpenCode instead of Anthropic's API.
Espressif's C framework turns cheap microcontrollers into edge AI agents you program through IM chat.
TokenHub exists because dropping a shared OpenAI key into a Slack channel does not scale past one invoice and zero accountability.
One desktop UI that wires together ComfyUI, OpenAI, Gemini, ModelScope, and a dozen other generative APIs—plus some very opinionated legal terms.
turbovec exists so you can index embeddings immediately—no training, no tuning, no rebuilds—and search them faster than FAISS in a fraction of the RAM.
WorldX turns one sentence into a self-running simulation of AI agents who gossip, scheme, and remember grudges without a script.
Dream Server exists because most people would rather pay OpenAI than spend a weekend hand-wiring Docker configs for local LLMs, RAG, and image generation.
It exists because cloud image generators deserve a local memory layer, a branching canvas, and a UI outside the chat thread.
It unifies Stable Diffusion, GGUF chat, Whisper, and Kokoro TTS into a single offline desktop GUI so you can skip cloud APIs, subscriptions, and censorship filters.
A Bittensor subnet that uses zero-knowledge proofs to verify miners actually ran the AI models they claim to.
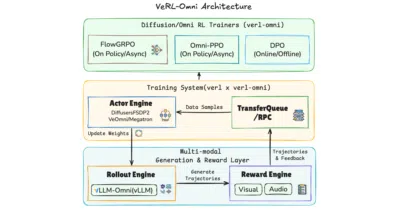
It split off from `verl` to give diffusion, video, and omni-modality models an RL post-training framework that doesn't treat them like chatbots.
AngelSlim integrates quantization, speculative decoding, and distillation so you can shrink and serve massive models from a single toolkit.
It turns your local machine into an OpenAI-compatible inference endpoint so agents and IDEs can run on offline models without reconfiguration.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.