01
Vincentwei1021/video-shotcraft
+92% /wk +252 ★/day→steady
It gives Claude Code and Codex a motion-design vocabulary—106 shot recipes, 161 previews, and a Remotion template—so they can direct cinematic product videos instead of generic slideshows.
It gives Claude Code and Codex a motion-design vocabulary—106 shot recipes, 161 previews, and a Remotion template—so they can direct cinematic product videos instead of generic slideshows.
It bundles the entire AI drama workflow—script, storyboard, voice, and final cut—into a single pipeline you can host yourself.
An agent skill that forces you to approve the visual metaphor and static layout before it spends your Gemini credits on video generation.
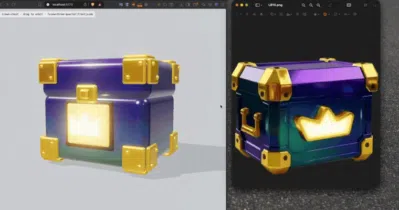
It exists to rebuild objects from reference photos as token-efficient, animation-ready Three.js code, using agent vision to gate quality before every sculpting pass.
OrkasVideoStudio gives coding agents a deterministic, local-first toolkit for composing, editing, and generating video from plain-language prompts.
A self-hostable infinite canvas that wires AI image generation, reference editing, and chat into one collaborative workspace.
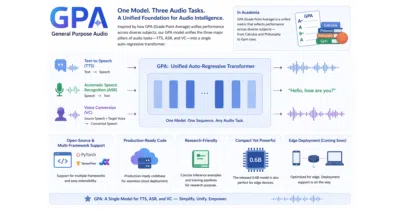
GPA aims to unify speech recognition, text-to-speech, and voice conversion in one compact autoregressive model so you can stop juggling separate audio pipelines.
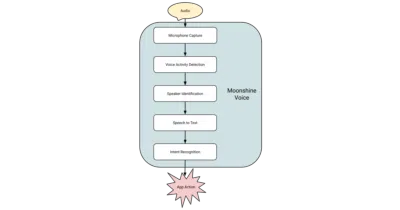
An on-device voice toolkit that ditches the 30-second window and redundant re-processing that makes Whisper feel sluggish for live speech.
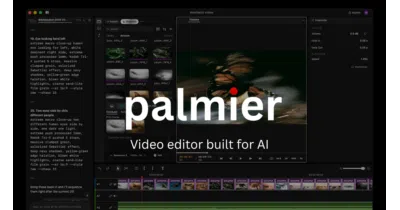
Palmier Pro exists to turn a Swift-native video editor into a shared workspace where AI agents can read and write the timeline via MCP.
Vocalinux is a fully offline, GPLv3 voice dictation app that pipes transcribed text into any Linux application on X11 or Wayland.
A Tauri desktop app that auto-detects a dozen local AI backends so you don't have to wrestle with Docker or API keys.
It exists because cloud image generators deserve a local memory layer, a branching canvas, and a UI outside the chat thread.
It unifies Stable Diffusion, GGUF chat, Whisper, and Kokoro TTS into a single offline desktop GUI so you can skip cloud APIs, subscriptions, and censorship filters.
A modular agent OS that directs Seedance 2.0 video generation with film-production discipline—shot contracts, continuity rules, and retake budgets—instead of vague prompt dumps.
Most AI image prompts are one-off text blobs; this repo distills 96 visual styles into structured JSON templates so you can swap variables without losing style direction.
LocalMiniDrama wires your API keys into a Vue+Electron pipeline that turns story outlines into short-form AI video without shipping data to anyone else's cloud.
Toonflow exists to turn a manuscript into an animated short drama without juggling five different browser tabs.
PixelRAG renders documents into screenshot tiles and retrieves them visually, preserving tables and layout that HTML parsers strip away.
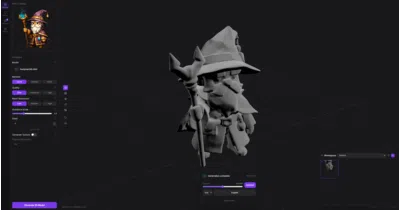
It wraps open-source image-to-3D models in a desktop app so your snapshots never leave your GPU.
FluidVoice brings fully offline speech-to-text and AI-enhanced formatting to any macOS text field, offering an open-source alternative to cloud dictation services.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.