openlake-project/openlake
An object store that treats the CPU as overhead
OpenLake wants storage to bypass the host entirely and land straight in GPU memory.
Velocity · 7d
+35
★ / day
Trend
↗accelerating
star history
What it does
OpenLake is a distributed S3-compatible object store written in Rust, built for the specific misery of feeding GPUs during LLM training and inference. It uses io_uring, pins one runtime per core with no work stealing, and runs the HTTP frontend and storage engine on the same thread so requests never cross core boundaries on the hot path.
The interesting bit The real bet is zerocopy: GPUDirect Storage and RDMA move data from peer NIC straight into GPU VRAM, skipping host memory and the page cache entirely. The README also claims a novel congestion control algorithm called “PacedRDMA” and SIMD-accelerated Reed-Solomon erasure coding. Whether the 6× throughput claim holds outside their own benchmarks is, naturally, their claim to verify.
Key highlights
- S3-compatible API; works with standard
awsCLI - Built on
compiocompletion-based runtime, Rust 1.91+ io_uringon Linux,kqueuefallback on macOS for dev builds- Includes a local benchmark CLI (
openlake bench) for quick smoke testing - Cluster config is plain TOML, one file per node
Caveats
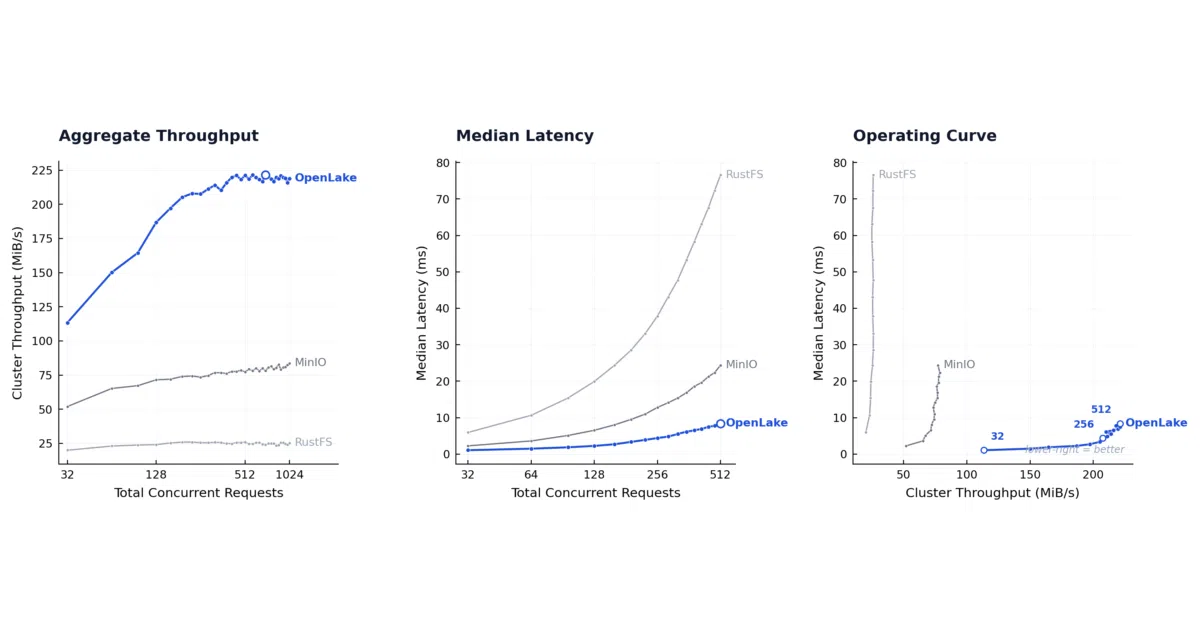
- The benchmark chart in the README is self-reported against MinIO and “RustFS” (likely typo for JuiceFS or similar) with no independent validation visible
- “Million+ IOPS within 1ms” and “6× higher throughput” are marketing-adjacent claims without disclosed test conditions
- GPUDirect Storage and RDMA require specific NVIDIA hardware and network setup; this is not a drop-in replacement for a standard S3 endpoint on commodity cloud instances
Verdict Worth watching if you’re running multi-node GPU clusters with InfiniBand or NVLink and your storage layer is actually the bottleneck. For a single-node setup or generic object storage needs, this is overkill with hardware lock-in.
Frequently asked
- What is openlake-project/openlake?
- OpenLake wants storage to bypass the host entirely and land straight in GPU memory.
- Is openlake open source?
- Yes — openlake-project/openlake is open source, released under the Apache-2.0 license.
- What language is openlake written in?
- openlake-project/openlake is primarily written in Rust.
- How popular is openlake?
- openlake-project/openlake has 2.2k stars on GitHub and is currently accelerating.
- Where can I find openlake?
- openlake-project/openlake is on GitHub at https://github.com/openlake-project/openlake.