Lynpoint/CyberVerse
Voice agents that remember you, delegate work, and move their lips
A self-hosted framework for building real-time voice-first AI agents that persist memory, delegate long tasks to background sub-agents, and optionally show up as lip-synced digital humans.
Velocity · 7d
+36
★ / day
Trend
↗accelerating
star history
What it does
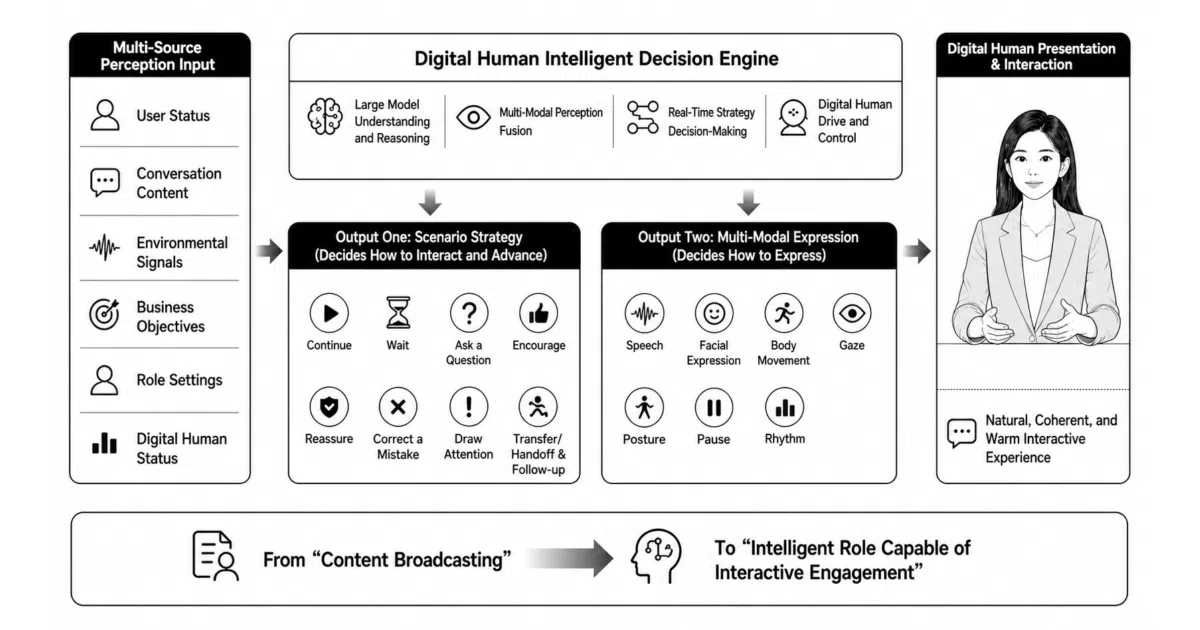
CyberVerse is a self-hosted framework for real-time, voice-first AI agents. It handles low-latency conversation over WebRTC, persists character-specific memory and conversation history to disk, and can ground responses in uploaded documents via RAG. If you want a visual presence, a single reference image can drive optional real-time lip-sync and facial animation through backends like FlashHead or LiveAct; disable it, and the same agent runs as a lean voice-only service.
The interesting bit
The architecture splits the agent into a foreground PersonaAgent that keeps the conversation flowing and handles interruptions, and background SubAgents that asynchronously tackle long-running jobs like research, summarization, or report generation. This prevents a tool call from freezing your voice turn, which is the kind of UX detail that separates a demo from a product.
Key highlights
- Modular pipeline: swap out LLMs, TTS, ASR, embedding models, RAG, and avatar backends via
cyberverse_config.yamland a web UI at/settings. - Runs fully offline in voice-only mode without a local GPU; avatar mode requires CUDA and separate model weights.
- WebRTC transport with optional LiveKit SFU or direct P2P, plus support for visual input from the user’s camera or screen share in omni sessions.
- Per-character configuration including voice cloning, welcome messages, personality, and persisted local memory.
- Licensed under GPL v3.
Caveats
- Even voice-only mode requires orchestrating Python, Go, Node, Conda, and FFmpeg locally, plus API keys for supported providers such as Alibaba Qwen or Volcengine Doubao.
- Avatar mode requires a CUDA 12.8+ GPU and downloading separate model weights for FlashHead or LiveAct.
- The README notes that demo characters are not bundled and are not provided for commercial use.
Verdict
Worth exploring if you want to self-host a conversational AI with persistent memory and an optional visual presence, but probably overkill if you just need a simple voice chatbot. Skip it if you’re allergic to multi-service local orchestration.
Frequently asked
- What is Lynpoint/CyberVerse?
- A self-hosted framework for building real-time voice-first AI agents that persist memory, delegate long tasks to background sub-agents, and optionally show up as lip-synced digital humans.
- Is CyberVerse open source?
- Yes — Lynpoint/CyberVerse is open source, released under the GPL-3.0 license.
- What language is CyberVerse written in?
- Lynpoint/CyberVerse is primarily written in Python.
- How popular is CyberVerse?
- Lynpoint/CyberVerse has 1.5k stars on GitHub and is currently accelerating.
- Where can I find CyberVerse?
- Lynpoint/CyberVerse is on GitHub at https://github.com/Lynpoint/CyberVerse.