ammaarreshi/gemma-chat
Vibe code at 30,000 feet, no Wi-Fi required
An Electron app that turns Apple Silicon Macs into fully offline coding agents using Google's Gemma 4 and Apple's MLX framework.
Not currently ranked — collecting fresh signals.
star history
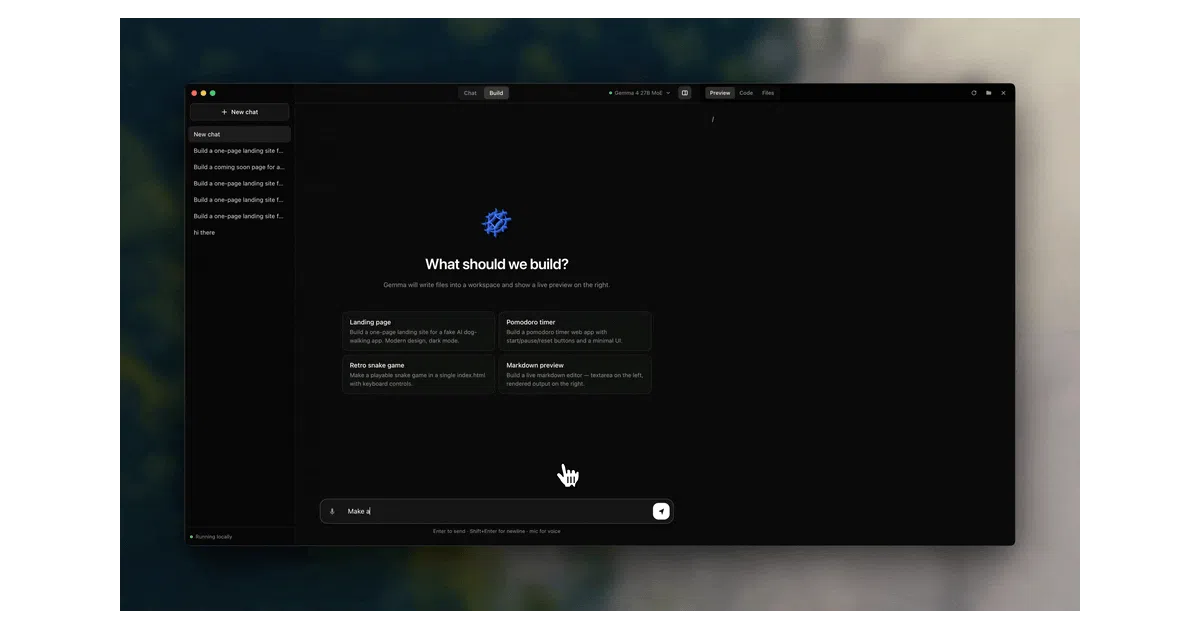
What it does
Gemma Chat is an Electron app that runs Google’s Gemma 4 model natively on Apple Silicon via Apple’s MLX framework. You describe a project in plain English, it generates multi-file HTML/CSS/JS projects, and you watch a live preview update as the model types. After a one-time ~3 GB model download, it needs no internet, no API keys, and no cloud.
The interesting bit
The agent loop streams tokens from a local MLX server, parses XML <action> blocks on the fly, and flushes partial file writes to disk every ~450 ms so the preview iframe reloads in real time. The author chose XML over JSON for tool calling because small models handle it more reliably — a pragmatic concession to local-model limitations.
Key highlights
- Build mode with sandboxed workspace + live preview canvas; Chat mode with tool use (web search, bash, calculator, URL fetch)
- Hot-swap between four Gemma 4 variants (1.5 GB to 18 GB) mid-conversation
- Local speech-to-text via in-browser Whisper (transformers.js WASM)
- Auto-provisions Python venv, installs MLX-LM, and downloads model on first launch
- Per-conversation filesystem isolation with local HTTP server for previews
Caveats
- macOS + Apple Silicon only; no Intel Mac or Linux/Windows support
- The 27B and 31B models need 16 GB+ and 32 GB+ RAM respectively
- Up to 40 agent rounds per user message — complex requests could get slow
Verdict
Grab this if you want a fully offline “vibe coding” setup on a recent Mac and don’t mind trading cloud-model smarts for privacy. Skip it if you need cross-platform support, collaborative features, or the reasoning power of frontier models.
Frequently asked
- What is ammaarreshi/gemma-chat?
- An Electron app that turns Apple Silicon Macs into fully offline coding agents using Google's Gemma 4 and Apple's MLX framework.
- Is gemma-chat open source?
- Yes — ammaarreshi/gemma-chat is open source, released under the MIT license.
- What language is gemma-chat written in?
- ammaarreshi/gemma-chat is primarily written in TypeScript.
- How popular is gemma-chat?
- ammaarreshi/gemma-chat has 1.4k stars on GitHub.
- Where can I find gemma-chat?
- ammaarreshi/gemma-chat is on GitHub at https://github.com/ammaarreshi/gemma-chat.