01
dbpedia-spotlight/dbpedia-spotlight
+0.1 ★/day→steady
The original DBpedia Spotlight entity linker still works, but the maintainers have packed up and left for a cleaner, Apache-licensed rewrite.
The original DBpedia Spotlight entity linker still works, but the maintainers have packed up and left for a cleaner, Apache-licensed rewrite.
A thin Python wrapper around Stanford's Java CoreNLP server, now officially abandoned in favor of Stanza.
A modular query engine that treats scattered RDF data as if it were one graph, no central warehouse required.
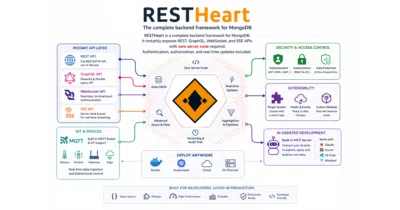
RESTHeart turns MongoDB into an MCP-native backend so Claude, Cursor, and other AI agents can read and write without custom integration code.
A Python library for building NLU-based chatbots with knowledge graphs, though you'll be doing plenty of configuration legwork yourself.
An R package for text analysis that streams data and parallelizes greedily instead of loading everything into RAM.
A legacy Excel-to-Neo4j tutorial that refuses to die, now with a modern GraphRAG sidecar and an AI agent skill.
cdQA was a Python toolkit for building closed-domain QA systems on your own documents, before its authors sent everyone to Haystack instead.
A local semantic search engine that lets developers query Stack Exchange dumps without opening a browser—or needing a network connection.
Chinese knowledge-graph QA bot you can run in a browser tab or hit via API.
A C++ similarity-search engine that tries to spare you from tuning HNSW/Faiss knobs by hand, wrapped in multi-language SDKs and a SQL layer.
A Python toolkit for Persian text processing, from normalization to dependency parsing, with models fetched automatically from Hugging Face.
A proxy that reranks search results with transformer models before your users ever see them.
A 560-star embedding toolkit is now a redirect to its spiritual successor—here's what happened, and where the bodies are buried.
A thin Flask wrapper that turns pretrained word embedding models into HTTP endpoints for similarity queries and vector lookups.
A local tool that lets you type "a line drawing of a woman facing left" and actually find the image—no cloud, no metadata, no filenames required.
A retrieval system that indexes individual phrases from all of Wikipedia so you can search by semantic meaning, not keyword matching.
A GitHub mirror of the original word2vec C implementation that applies community patches so it compiles on modern systems.
A Dockerized bridge that lets BERT turn your text into vectors so Elasticsearch can search by meaning, not just keywords.
A collection of runnable examples for image, video, audio, text, and even molecular search using the Towhee embedding pipeline.
heatdrop uses Google Analytics to see which pages get read — nothing else. Your call. How we handle data.