dselivanov/text2vec
R's text toolkit that refuses to hold everything in memory
An R package for text analysis that streams data and parallelizes greedily instead of loading everything into RAM.
Not currently ranked — collecting fresh signals.
star history
What it does
text2vec is an R package for text analysis and NLP that wraps vectorization, topic modeling, distance calculations, and GloVe word embeddings behind a small, consistent API. It targets the standard pipeline — turn text into numbers, model it, measure it — without sprawling function lists.
The interesting bit
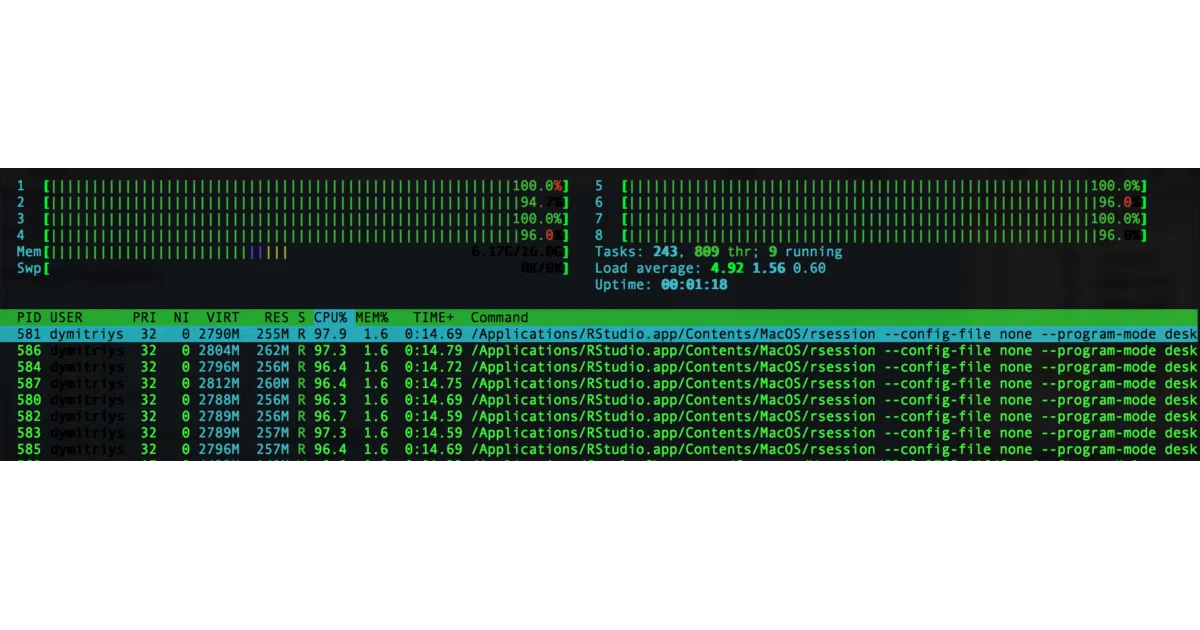
The package leans on C++ and OpenMP for speed, but the real architectural bet is streaming: it uses iterators to avoid loading full datasets into RAM. On UNIX systems, fork-based backends can push embarrassingly parallel tasks (like vectorization) across cores with near-linear scaling. The README’s htop screenshot is a flex, but also a hint at the design priority.
Key highlights
- Small API surface — deliberately few functions, unified interface across tasks
- Memory-conscious — streaming via iterators; data stays out of RAM when possible
- Multi-threaded — OpenMP for some operations, fork-based parallelism for others
- C++ under the hood — performance claims grounded in compiled code, not R loops
- Covers the bases — includes GloVe embeddings, LDA topic modeling, and distance metrics
Caveats
- The README is light on concrete benchmarks beyond the htop image; actual speedups depend on your hardware and data shape
- Near-linear scalability is specifically for “embarrassingly parallel tasks” — not everything parallelizes equally
Verdict
Worth a look if you’re doing text work in R and hitting memory walls with tidyverse or base approaches. Less compelling if you’re already in Python’s ecosystem or need deep neural architectures — this is classical NLP tooling, not transformers.
Frequently asked
- What is dselivanov/text2vec?
- An R package for text analysis that streams data and parallelizes greedily instead of loading everything into RAM.
- Is text2vec open source?
- Yes — dselivanov/text2vec is an open-source project tracked on heatdrop.
- What language is text2vec written in?
- dselivanov/text2vec is primarily written in R.
- How popular is text2vec?
- dselivanov/text2vec has 875 stars on GitHub.
- Where can I find text2vec?
- dselivanov/text2vec is on GitHub at https://github.com/dselivanov/text2vec.