Hironsan/bertsearch
Elasticsearch learns to read between the lines
A Dockerized bridge that lets BERT turn your text into vectors so Elasticsearch can search by meaning, not just keywords.
Not currently ranked — collecting fresh signals.
star history
What it does
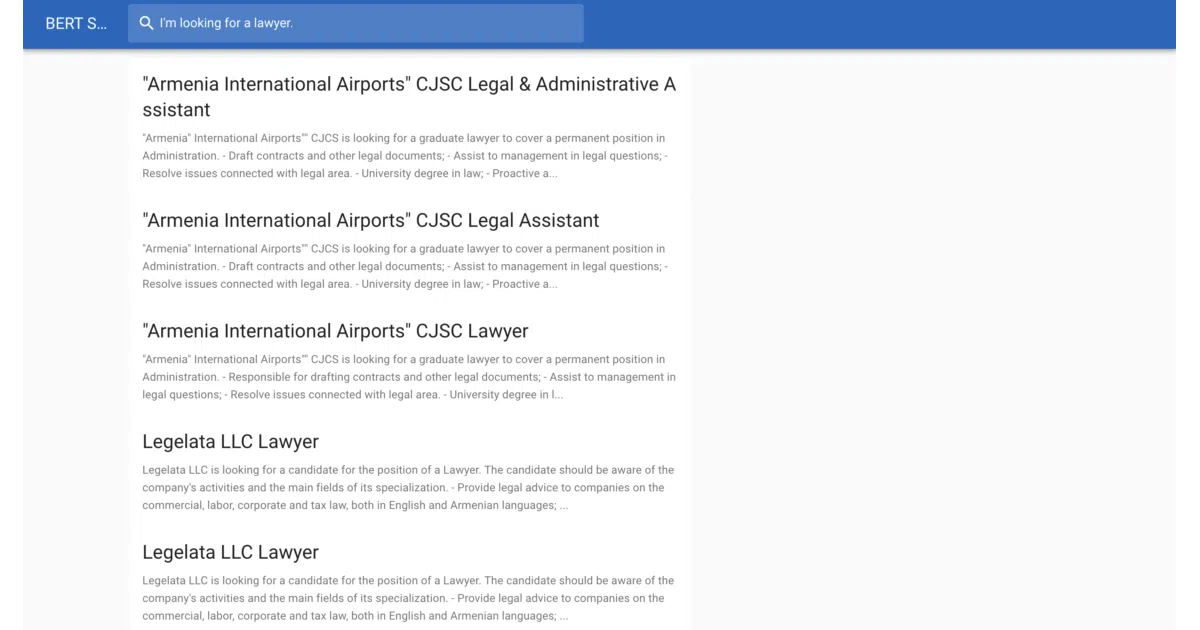
bertsearch is a reference setup, not a library. You bring a pretrained BERT model, feed documents through it to generate 768-dimensional embeddings, store those vectors in Elasticsearch’s dense_vector field, and query via a small Flask UI. The README walks through a job-search demo: CSV in, vectors out, browser open.
The interesting bit
The heavy lifting is the plumbing. The project wires together three containers—Elasticsearch, a BERT inference service, and a Flask frontend—so you don’t have to. The actual “search” is Elasticsearch’s cosine-similarity on dense vectors; BERT just supplies the embeddings. It’s a clean illustration of how to bolt semantic search onto a traditional engine without rewriting either.
Key highlights
- Pre-baked Docker Compose setup:
docker-compose upand you’re running - Supports Google’s original pretrained BERT models (Base/Large, cased/uncased, multilingual, Chinese)
- Uses Elasticsearch’s native
dense_vectortype—no custom plugin needed - Includes end-to-end scripts: create index, vectorize CSV, bulk-index, search
- Flask UI served on localhost:5000 for manual queries
Caveats
- README warns BERT container needs >8GB RAM; this will not run happily on a small laptop
- No mention of GPU support, model quantization, or approximate nearest-neighbor indexing—scaling beyond toy data is an exercise for the reader
- Last commit activity and BERT model links suggest this targets the 2018-era Google BERT release, not modern successors
Verdict
Good for developers who want a concrete, working skeleton for semantic search with Elasticsearch and need to convince a team (or themselves) that the pieces fit. Skip it if you need production-scale vector search, modern models, or a maintained framework—this is a proof of concept that stayed one.
Frequently asked
- What is Hironsan/bertsearch?
- A Dockerized bridge that lets BERT turn your text into vectors so Elasticsearch can search by meaning, not just keywords.
- Is bertsearch open source?
- Yes — Hironsan/bertsearch is open source, released under the MIT license.
- What language is bertsearch written in?
- Hironsan/bertsearch is primarily written in Python.
- How popular is bertsearch?
- Hironsan/bertsearch has 897 stars on GitHub.
- Where can I find bertsearch?
- Hironsan/bertsearch is on GitHub at https://github.com/Hironsan/bertsearch.