roshan-research/hazm
Persian NLP that handles the zero-width non-joiner so you don't have to
A Python toolkit for Persian text processing, from normalization to dependency parsing, with models fetched automatically from Hugging Face.
Not currently ranked — collecting fresh signals.
star history
What it does
Hazm is a Python library for processing Persian (Farsi) text. It covers the standard NLP pipeline—normalization, tokenization, lemmatization, POS tagging, chunking, dependency parsing, and word/sentence embeddings—plus utilities for reading popular Persian corpora. Models download and cache automatically from Hugging Face Hub.
The interesting bit
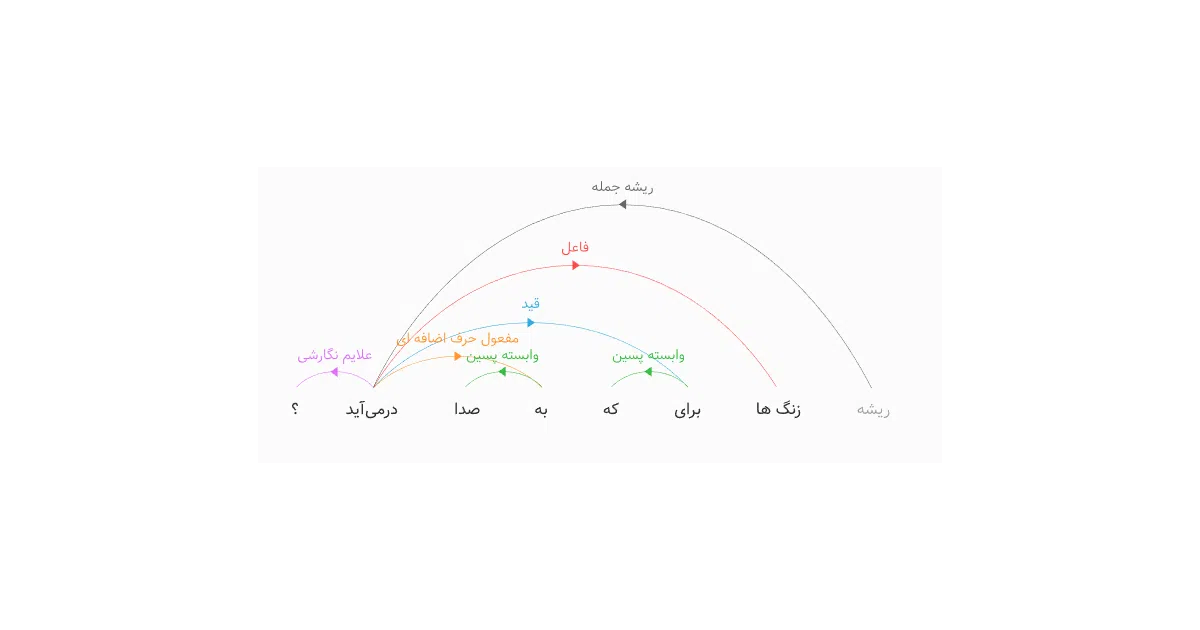
Persian text normalization is fiddly work: diacritics, half-spaces, and the zero-width non-joiner (ZWNJ) all need correction before anything else works. Hazm bakes this in as a first-class step rather than leaving it as an exercise. The lemmatizer also returns compound roots (e.g., نوشت#نویس for “مینویسیم”), which is more informative than a simple stem.
Key highlights
- POS tagger hits 98.8% accuracy; dependency parser at 85.6% on the project’s own evaluation
- Hugging Face integration means no manual model downloads—just pass
repo_idandmodel_filename - Supports FastText word embeddings and sentence vectors via
sent2vec - Includes ready-made corpus readers for common Persian datasets
- Requires Python 3.12+
Caveats
- The README lists both legacy and “Spacy” prefixed modules (SpacyPOSTagger, SpacyChunker, etc.) with different metrics, but doesn’t clarify whether these are spaCy wrappers or independent implementations
- Dependency parser output is raw nested dictionaries, not a graph object—usable, but you’ll do your own traversal
Verdict
Worth a look if you’re building Persian-language pipelines and want batteries-included preprocessing. Skip it if you’re already invested in spaCy or transformers and prefer to roll your own Persian normalization.
Frequently asked
- What is roshan-research/hazm?
- A Python toolkit for Persian text processing, from normalization to dependency parsing, with models fetched automatically from Hugging Face.
- Is hazm open source?
- Yes — roshan-research/hazm is open source, released under the MIT license.
- What language is hazm written in?
- roshan-research/hazm is primarily written in Python.
- How popular is hazm?
- roshan-research/hazm has 1.4k stars on GitHub.
- Where can I find hazm?
- roshan-research/hazm is on GitHub at https://github.com/roshan-research/hazm.