zai-org/GLM-5
An open 744B-parameter model that improves with more thinking time
GLM-5 is a family of massive open-weight models built for long-horizon agentic engineering, where the flagship GLM-5.1 keeps improving across hundreds of rounds instead of burning out early.
Velocity · 7d
+59
★ / day
Trend
↗accelerating
star history
What it does
GLM-5 is a 744B-parameter (40B active) open-weight model family targeting complex systems engineering and long-horizon agentic tasks. It scales pre-training to 28.5T tokens and integrates DeepSeek Sparse Attention to keep deployment costs in check. GLM-5.1 is the newer flagship focused on agentic engineering and coding, achieving state-of-the-art results on SWE-Bench Pro and sustained performance over thousands of tool calls.
The interesting bit
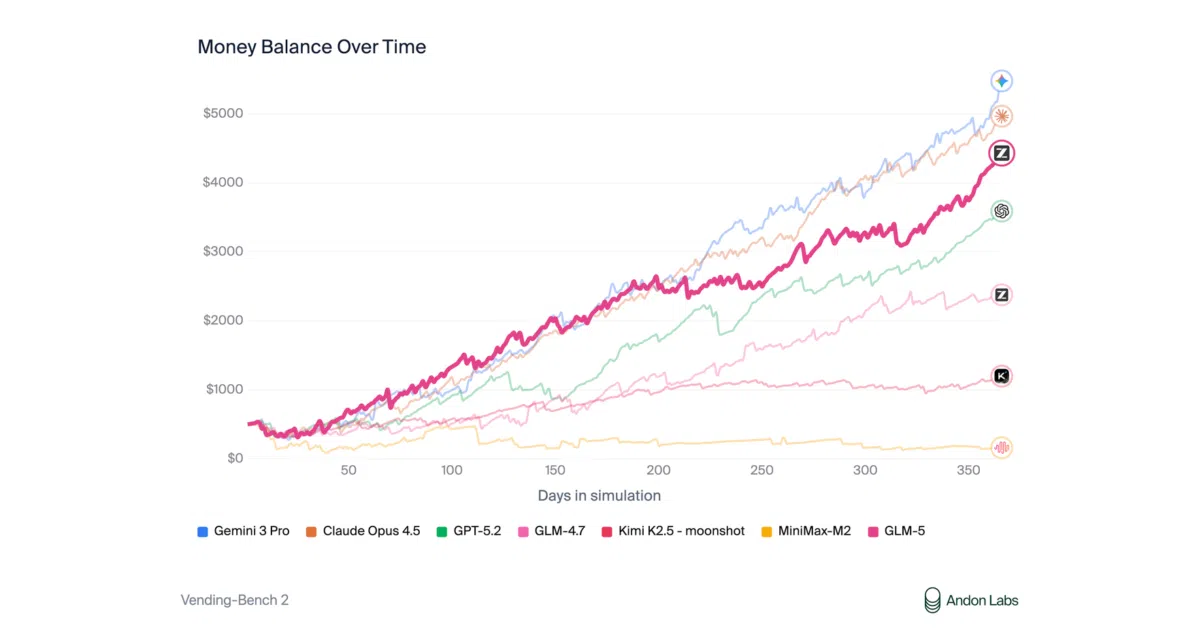
Most models exhaust their best ideas in the first few passes and then plateau; GLM-5.1 is explicitly trained to revisit its reasoning and revise strategy across hundreds of rounds. On Vending Bench 2—a year-long simulated business benchmark—it ranked #1 among open-source models, finishing with a balance of $4,432 and approaching Claude Opus 4.5.
Key highlights
- 744B total parameters with 40B active; BF16 and FP8 weights available on Hugging Face and ModelScope.
- Uses DeepSeek Sparse Attention (DSA) to cut deployment costs without sacrificing long-context windows.
- Post-trained with an asynchronous RL infrastructure called
slimethat the team built to improve training throughput. - GLM-5.1 achieves state-of-the-art on SWE-Bench Pro and leads on NL2Repo and Terminal-Bench 2.0.
- Supports local inference through vLLM, SGLang, xLLM, and Ktransformers.
Caveats
- The README flags a tool-call parsing issue when using speculative decoding with vLLM, requiring the vLLM main branch as a workaround.
- These are enormous models; local deployment demands significant GPU resources.
- GLM-5.1 is described as arriving on the chat platform “in the coming days,” so some access channels are not yet live.
Verdict
Worth evaluating if you are building autonomous coding agents or testing long-horizon reasoning, but likely overkill for simple chat or short-context tasks.
Frequently asked
- What is zai-org/GLM-5?
- GLM-5 is a family of massive open-weight models built for long-horizon agentic engineering, where the flagship GLM-5.1 keeps improving across hundreds of rounds instead of burning out early.
- Is GLM-5 open source?
- Yes — zai-org/GLM-5 is open source, released under the Apache-2.0 license.
- How popular is GLM-5?
- zai-org/GLM-5 has 6.7k stars on GitHub and is currently accelerating.
- Where can I find GLM-5?
- zai-org/GLM-5 is on GitHub at https://github.com/zai-org/GLM-5.