yifanfeng97/Hyper-Extract
A CLI that turns PDFs into hypergraphs before you finish your coffee
Hyper-Extract wraps a dozen LLM extraction engines into one command that spits out knowledge graphs, hypergraphs, or spatio-temporal structures from raw text.
Velocity · 7d
+9.1
★ / day
Trend
→steady
star history
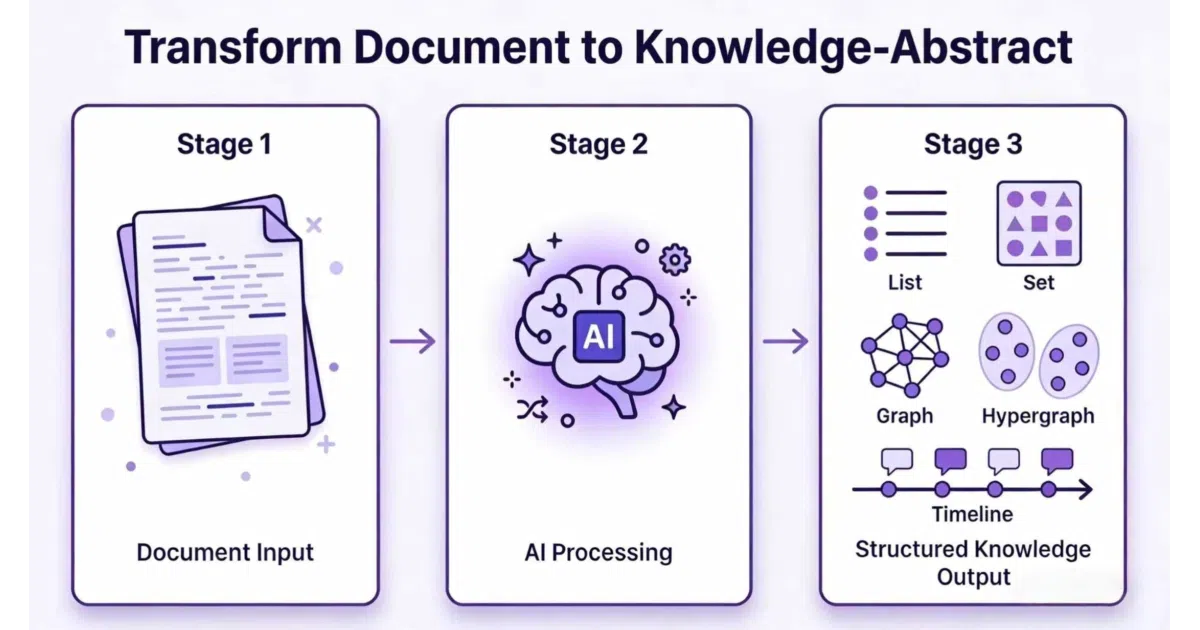
What it does Hyper-Extract is a Python CLI and library that feeds documents to LLMs and returns structured knowledge in eight shapes: simple lists, Pydantic models, graphs, hypergraphs, temporal graphs, spatial graphs, and the full spatio-temporal combo. You pick a YAML template (80+ ship for finance, legal, medical, and general use), point it at a file, and get typed output. It also incrementally evolves knowledge bases as new documents arrive.
The interesting bit The project treats “extraction engine” as a swappable layer. It bundles GraphRAG, LightRAG, Hyper-RAG, KG-Gen, Cog-RAG and others behind a single interface, then maps their outputs onto strongly-typed structures via Pydantic. The hypergraph and spatio-temporal support is genuinely unusual in this space — most tools stop at flat knowledge graphs.
Key highlights
- One CLI command (
he parse) from document to graph;he showopens an interactive visualization - 80+ zero-code YAML templates across six domains, or write your own with a documented schema
- Local deployment via vLLM (tested with Qwen3.5-9B + bge-m3) for air-gapped runs
- Verified against OpenAI, Alibaba Bailian, and local vLLM endpoints; requires
json_schemaor function-calling support - Incremental ingestion: feed new docs to expand an existing knowledge base without rebuilding
Caveats
- The comparison table claims features for competitors that are hard to verify (e.g., “Multi-language” checks are based on the author’s own assessment)
- Only three model families are verified; your favorite local model may lack the structured-output capability it needs
- The “10+ extraction engines” include some that are more like configuration variants than distinct algorithms
Verdict Worth a look if you regularly turn messy documents into structured knowledge and want one tool that spans lists to hypergraphs. Skip it if you need battle-tested extraction without LLM hallucination risks, or if your models don’t support strict JSON schema output.
Frequently asked
- What is yifanfeng97/Hyper-Extract?
- Hyper-Extract wraps a dozen LLM extraction engines into one command that spits out knowledge graphs, hypergraphs, or spatio-temporal structures from raw text.
- Is Hyper-Extract open source?
- Yes — yifanfeng97/Hyper-Extract is an open-source project tracked on heatdrop.
- What language is Hyper-Extract written in?
- yifanfeng97/Hyper-Extract is primarily written in Python.
- How popular is Hyper-Extract?
- yifanfeng97/Hyper-Extract has 3.1k stars on GitHub and is currently holding steady.
- Where can I find Hyper-Extract?
- yifanfeng97/Hyper-Extract is on GitHub at https://github.com/yifanfeng97/Hyper-Extract.