wdndev/tiny-llm-zh
A from-scratch Chinese LLM that shows its work, low scores and all
This project exists to teach the full LLM lifecycle—tokenizer, pre-training, alignment, and deployment—using Chinese models small enough to train without a corporate cluster.
Not currently ranked — collecting fresh signals.
star history
What it does
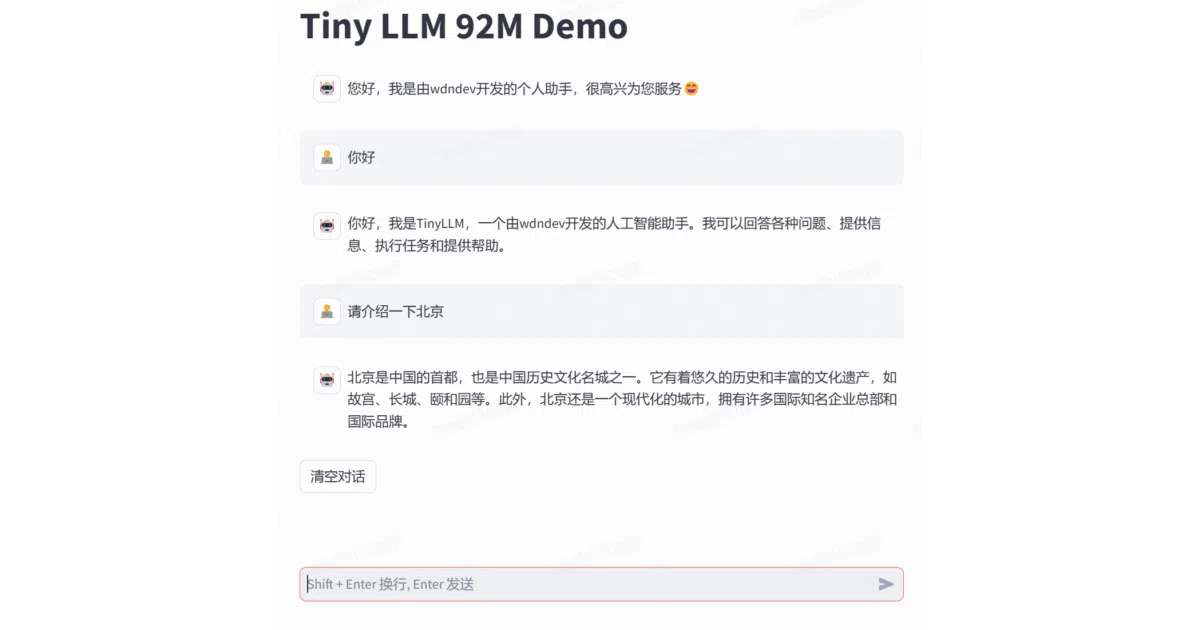
Tiny LLM zh is an educational Chinese language model built from the ground up to demonstrate the complete production pipeline. It covers tokenizer construction, pre-training on 42 billion tokens, supervised fine-tuning on four million instruction pairs, RLHF/DPO alignment, evaluation, and deployment. The architecture follows a Llama 2-style design with RMSNorm, RoPE, and multi-head attention, scaled down to sizes ranging from 16 million to 1.5 billion parameters.
The interesting bit
The author openly admits the model’s benchmark scores are low—its 92M chat variant scores roughly 27 on both C-Eval and CMMLU—because the primary goal was walking through every stage of the pipeline rather than chasing leaderboards. That honesty is the feature; you get to see a real, imperfect training run with all data and scripts published, including the pre-training corpus and tokenizer construction code.
Key highlights
- Full pipeline transparency: tokenizer, pre-training, SFT, RLHF/DPO, evaluation, and deployment scripts are all public.
- Scales from 16M to 1.5B parameters, with a 92M variant already hosted on Hugging Face and ModelScope for immediate inference.
- Supports advanced training infrastructure like DeepSpeed with ZeRO optimization and multi-node/multi-GPU setups.
- Includes a Mixture-of-Experts branch with shared and balanced expert routing.
- Inference support spans Transformers, vLLM, and a custom fork of llama.cpp for edge deployment.
Caveats
- Benchmark scores are explicitly noted as low, and generated outputs contain factual errors; this is framed as a consequence of prioritizing pipeline completion over model polish.
- Detailed documentation for data processing and training procedures is still being organized in the
docfolder. - vLLM and llama.cpp integrations require manual patches into those frameworks because the custom model architecture is not natively supported.
Verdict
Ideal for students and engineers who want to see how a Chinese LLM is built from tokenizer to deployment on limited resources. Skip it if you need a production-ready model or state-of-the-art Chinese reasoning out of the box.
Frequently asked
- What is wdndev/tiny-llm-zh?
- This project exists to teach the full LLM lifecycle—tokenizer, pre-training, alignment, and deployment—using Chinese models small enough to train without a corporate cluster.
- Is tiny-llm-zh open source?
- Yes — wdndev/tiny-llm-zh is an open-source project tracked on heatdrop.
- What language is tiny-llm-zh written in?
- wdndev/tiny-llm-zh is primarily written in Python.
- How popular is tiny-llm-zh?
- wdndev/tiny-llm-zh has 1.1k stars on GitHub.
- Where can I find tiny-llm-zh?
- wdndev/tiny-llm-zh is on GitHub at https://github.com/wdndev/tiny-llm-zh.